In this section we describe the parallel implementation of LU factorization, with partial pivoting over rows, for a block-partitioned matrix. The matrix, A, to be factored is assumed to have a block cyclic decomposition, and at the end of the computation is overwritten by the lower and upper triangular factors, L and U. This implicitly determines the decomposition of L and U. Quite a high-level description is given here since the details of the parallel implementation involve optimization issues that will be addressed in Section 7.
Figure 10: Block cyclic decomposition of a ![]() matrix
with a block size of
matrix
with a block size of ![]() , onto a
, onto a ![]() process template.
Each small rectangle represents one matrix block - individual matrix
elements are not shown. In (a), shading is used to emphasize the process
template that is periodically stamped over the matrix, and each block is labeled
with the process to which it is assigned. In (b), each shaded region shows the
blocks in one process, and is labeled with the
corresponding global block indices. In both figures, the black rectangles
indicate the blocks assigned to process (0,0).
process template.
Each small rectangle represents one matrix block - individual matrix
elements are not shown. In (a), shading is used to emphasize the process
template that is periodically stamped over the matrix, and each block is labeled
with the process to which it is assigned. In (b), each shaded region shows the
blocks in one process, and is labeled with the
corresponding global block indices. In both figures, the black rectangles
indicate the blocks assigned to process (0,0).
![]()
Figure 11: The same matrix decomposition as shown in Figure
10, but
for a template offset of 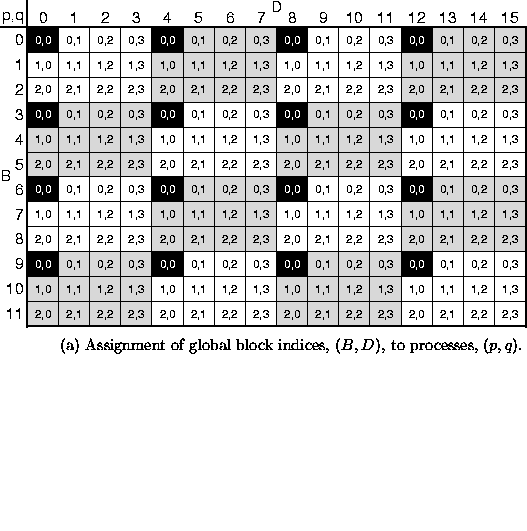 . Dashed entries in (b) indicate
that the block does not contain any data. In both figures, the black rectangles
indicate the blocks assigned to process (0,0).
. Dashed entries in (b) indicate
that the block does not contain any data. In both figures, the black rectangles
indicate the blocks assigned to process (0,0).
![]()
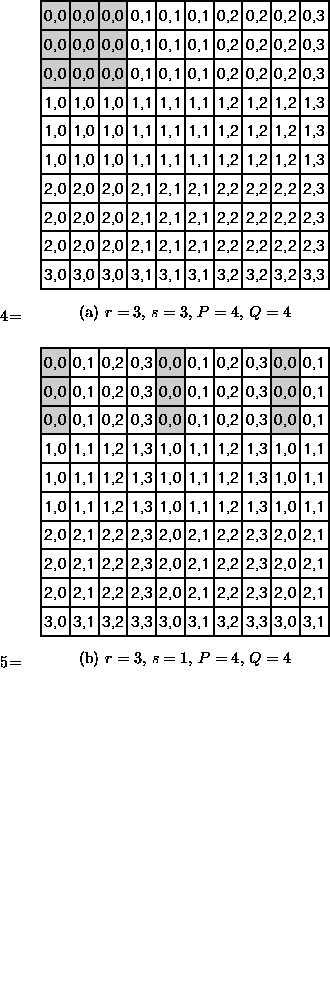
Figure 12: These 4 figures show different ways of decomposing
a
matrix. Each cell represents a matrix element, and is labeled by the position,
(p,q), in the template of the process to which it is assigned.
To emphasize the pattern of decomposition, the matrix entries assigned to the
process in the first row and column of the template are shown shaded,
and each separate shaded region represents a matrix block.
Figures (a) and (b) show block and cyclic row-oriented
decompositions, respectively, for 4 nodes.
In figures (c)
and (d) the corresponding column-oriented decompositions are shown.
Below each figure we give the values of r, s, P, and Q
corresponding to the decomposition. In all cases  .
.

Figure 13: These 4 figures show different ways of decomposing
a matrix over 16 processes arranged as a ![]() template.
Below each figure we give the values of r, s, P, and Q
corresponding to the decomposition. In all cases .
template.
Below each figure we give the values of r, s, P, and Q
corresponding to the decomposition. In all cases .
The sequential LU factorization algorithm
described in Section 4.1 uses square blocks.
Although in the parallel algorithm
we could choose to decompose the matrix using nonsquare blocks, this
would result in a more complicated code, and additional sources of
concurrent overhead. For LU factorization we, therefore, restrict the
decomposition to use only square blocks, so that the blocks used
to decompose the matrix are the same as those used to partition the
computation. If the block size is ![]() , then an
, then an ![]() matrix consists of
matrix consists of ![]() blocks, where and
blocks, where and
 .
.
As discussed in Section 4.1,
LU factorization proceeds in a series
of sequential steps indexed by ![]() , in each of which the
following three tasks are performed,
, in each of which the
following three tasks are performed,
We now consider the parallel implementation of each of these tasks. The computation in the factorization step involves a single column of blocks, and these lie in a single column of the process template. In the kth factorization step, each of the r columns in block column k is processed in turn. Consider the ith column in block column k. The pivot is selected by finding the element with largest absolute value in this column between row kr+i and the last row, inclusive. The elements involved in the pivot search at this stage are shown shaded in Figure 14. Having selected the pivot, the value of the pivot and its row are broadcast to all other processors. Next, pivoting is performed by exchanging the entire row kr+i with the row containing the pivot. We exchange entire rows, rather than just the part to the right of the columns already factored, in order to simplify the application of the pivots to the righthand side in any subsequent solve phase. Finally, each value in the column below the pivot is divided by the pivot. If a cyclic column decomposition is used, like that shown in Figure 12(d), only one processor is involved in the factorization of the block column, and no communication is necessary between the processes. However, in general P processes are involved, and communication is necessary in selecting the pivot, and exchanging the pivot rows.
![]()
Figure 14: This figure shows pivoting for step i of the kth stage
of LU factorization. The element with largest absolute value in the
gray shaded part of column kr+i is found, and the row containing it is
exchanged with row kr+i. If the rows exchanged lie in different processes,
communication may be necessary.
The solution of the lower triangular system ![]() to
evaluate the kth block row of U involves a single row of blocks, and
these lie in a single row of the process template.
If a cyclic row decomposition is
used, like that shown in Figure 12(b), only one processor is
involved in the triangular solve, and no communication is necessary between
the processes. However, in general Q processes are involved, and communication
is necessary to broadcast the lower triangular matrix,
to
evaluate the kth block row of U involves a single row of blocks, and
these lie in a single row of the process template.
If a cyclic row decomposition is
used, like that shown in Figure 12(b), only one processor is
involved in the triangular solve, and no communication is necessary between
the processes. However, in general Q processes are involved, and communication
is necessary to broadcast the lower triangular matrix, ![]() , to all
processes in the row. Once this has been done, each process in the row
independently performs a lower triangular solve for the blocks of C that it
holds.
, to all
processes in the row. Once this has been done, each process in the row
independently performs a lower triangular solve for the blocks of C that it
holds.
The communication necessary to update the trailing submatrix at step k
takes place in two steps. First, each process holding part of ![]() broadcasts these blocks to the other processes in the same row of the template.
This may be done in conjunction with the broadcast of
broadcasts these blocks to the other processes in the same row of the template.
This may be done in conjunction with the broadcast of ![]() , mentioned in the
preceding paragraph, so that all of the factored panel is broadcast together.
Next, each process holding part of
, mentioned in the
preceding paragraph, so that all of the factored panel is broadcast together.
Next, each process holding part of ![]() broadcasts these blocks to the other processes in the same column of
the template. Each process can then complete the update of the
blocks that it holds with no further communication.
broadcasts these blocks to the other processes in the same column of
the template. Each process can then complete the update of the
blocks that it holds with no further communication.
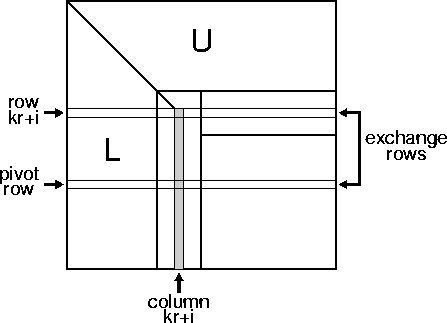
Figure 15: Pseudocode for the basic parallel
block-partitioned LU factorization algorithm. This code is executed by each
process. The first box inside the k loop factors the kth column of
blocks. The second box solves a lower triangular system to evaluate
the kth row of blocks of U, and the third box updates the trailing
submatrix. The template offset is given by ![]() , and (p,q) is
position of a process in the template.
, and (p,q) is
position of a process in the template.
A pseudocode outline of the parallel LU factorization algorithm is given in Figure 15. There are two points worth noting in Figure 15. First, the triangular solve and update phases operate on matrix blocks and may, therefore, be done with parallel versions of the Level 3 BLAS (specifically, xTRSM and xGEMM, respectively). The factorization of the column of blocks, however, involves a loop over matrix columns. Hence, is it not a block-oriented computation, and cannot be performed using the Level 3 BLAS. The second point to note is that most of the parallelism in the code comes from updating the trailing submatrix since this is the only phase in which all the processes are busy.
Figure 15 also shows quite clearly where communication is required; namely, in finding the pivot, exchanging pivot rows, and performing various types of broadcast. The exact way in which these communications are done and interleaved with computation generally has an important effect on performance, and will be discussed in more detail in Section 7.
Figure 15
refers to broadcasting data to all processes in the same row or
column of the template. This is a common operation in parallel linear
algebra algorithms, so the idea will be described here in a little more
detail. Consider, for example, the task of broadcasting the lower
triangular block, ![]() , to all processes in the same row of the template,
as required before solving
, to all processes in the same row of the template,
as required before solving ![]() . If
. If ![]() is in process (p,q),
then it will be broadcast to all processes in row p of the process
template. As a second example, consider the broadcast of
is in process (p,q),
then it will be broadcast to all processes in row p of the process
template. As a second example, consider the broadcast of ![]() to all
processes in the same template row, as required before updating the
trailing submatrix. This type of ``rowcast'' is shown schematically in
Figure 16(a).
If
to all
processes in the same template row, as required before updating the
trailing submatrix. This type of ``rowcast'' is shown schematically in
Figure 16(a).
If ![]() is in column q of the template, then
each process (p,q) broadcasts its blocks of
is in column q of the template, then
each process (p,q) broadcasts its blocks of ![]() to the other processes
in row p of the template. Loosely speaking, we can say that
to the other processes
in row p of the template. Loosely speaking, we can say that ![]() and
and
![]() are broadcast along the rows of the template. This type of
data movement is the same as that performed by the Fortran 90 routine
SPREAD
[7].
The broadcast of
are broadcast along the rows of the template. This type of
data movement is the same as that performed by the Fortran 90 routine
SPREAD
[7].
The broadcast of ![]() to all processes in the same template
column is very similar. This type of communication is sometimes referred to as a
``colcast'', and is shown in Figure 16(b).
to all processes in the same template
column is very similar. This type of communication is sometimes referred to as a
``colcast'', and is shown in Figure 16(b).
![]()
Figure 16: Schematic representation of broadcast along rows and columns of a
![]() process template. In (a), each shaded process broadcasts
to the processes in the same row of the process template. In (b), each
shaded process broadcasts to the processes in the same column of the
process template.
process template. In (a), each shaded process broadcasts
to the processes in the same row of the process template. In (b), each
shaded process broadcasts to the processes in the same column of the
process template.