




Next: Related Eigenproblems
Up: Hermitian Eigenproblems J.
Previous: Conditioning
Contents
Index
Specifying an Eigenproblem
The following eigenproblems are typical, both because they arise naturally
in applications and because we have good algorithms for them:
- Compute all the eigenvalues to some specified accuracy.
- Compute eigenvalues
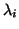 for some specified set of subscripts
for some specified set of subscripts
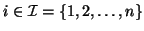 ,
including the special cases of the largest
,
including the special cases of the largest 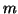 eigenvalues
eigenvalues
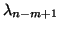 through
through
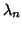 , and the smallest eigenvalues
, and the smallest eigenvalues 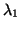 through
through 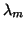 .
Again, the desired accuracy may be specified.
.
Again, the desired accuracy may be specified.
- Compute all the eigenvalues within a given subset of the real axis,
such as
the interval
![$[\alpha, \beta]$](img202.png) . Again, the desired accuracy may be specified.
. Again, the desired accuracy may be specified.
- Count all the eigenvalues in the interval
.
This does not require computing the eigenvalues in
,
and so can be much cheaper.
- Compute a certain number of eigenvalues closest to a given value
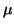 .
.
For each of these possibilities (except 4) the user can also compute the
corresponding eigenvectors.
For the eigenvalues that are clustered together,
the user may choose to compute the associated invariant subspace,
since in this case the individual eigenvectors can be very ill-conditioned,
while the invariant subspace may be less so.
Finally, for any of these quantities, the user might also want to
compute its condition number.
Even though we have effective algorithms for these problems,
we cannot necessarily solve all large scale problems
in an amount of time and space acceptable to all users.
Next: Related Eigenproblems
Up: Hermitian Eigenproblems J.
Previous: Conditioning
Contents
Index
Susan Blackford
2000-11-20