The Intel Touchstone Delta computer system is 16 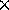 32 mesh of i860
processors with a wormhole routing interconnection network [41],
located at the California Institute of Technology on behalf of the
Concurrent Supercomputing Consortium.
The Delta's communication characteristics are described in [43].
32 mesh of i860
processors with a wormhole routing interconnection network [41],
located at the California Institute of Technology on behalf of the
Concurrent Supercomputing Consortium.
The Delta's communication characteristics are described in [43].
In order to implement Algorithm 1, it was natural to rely on the ScaLAPACK 1.0 library (beta version) [26]. This choice requires us to exploit two key design features of this package. First, the ScaLAPACK library relies on the Parallel Block BLAS (PB-BLAS)[15], which hides much of the interprocessor communication. This hiding of communication makes it possible to express most algorithms using only the PB-BLAS, thus avoiding explicit calls to communication routines. The PB-BLAS are implemented on top of calls to the BLAS and to the Basic Linear Algebra Communication Subroutines (BLACS)[25]. Second, ScaLAPACK assumes that the data is distributed according to the square block cyclic decomposition scheme, which allows the routines to achieve well balanced computations and to minimize communication costs. ScaLAPACK includes subroutines for LU, QR and Cholesky factorizations, which we use as building blocks for our implementation. The PUMMA routines [16] provide the required matrix multiplication.

Figure 2: Performance of ScaLAPACK 1.0 (beta version) subroutines on 256
(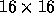 ) PEs Intel Touchstone Delta system.
) PEs Intel Touchstone Delta system.
The matrix inversion is done in two steps. After the LU factorization has
been computed, the upper triangular 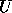 matrix is inverted, and
matrix is inverted, and 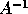 is
obtained by substitution with
is
obtained by substitution with 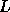 . Using blocked operations
leads to performance comparable to that obtained for LU factorization.
. Using blocked operations
leads to performance comparable to that obtained for LU factorization.
The implementation of the QR factorization with or without column pivoting is based on the parallel algorithm presented by Coleman and Plassmann [18]. The QR factorization with column pivoting has a much larger sequential component, processing one column at a time, and needs to update the norms of the column vectors at each step. This makes using blocked operations impossible and induces high synchronization overheads. However, as we will see, the cost of this step remains negligible in comparison with the time spent in the Newton iteration. Unlike QR factorization with pivoting, the QR factorization without pivoting and the post- and pre-multiplication by an orthogonal matrix do use blocked operations.
Figure 2 plots the timing results obtained by the PUMMA package using the BLACS for the general matrix multiplication, and ScaLAPACK 1.0 (beta version) subroutines for the matrix inversion, QR decomposition with and without column pivoting. Corresponding tabular data can be found in the Appendix.
To measure the efficiency of Algorithm 1,
we generated random matrices of different sizes, all of whose entries
are normally distributed with mean 0 and variance 1.
All computations were performed in real double precision arithmetic.
Table 1 lists the measured results of the backward
error, the number of Newton iterations,
the total CPU time and the megaflops rate.
In particular, the second column of the table contains the backward errors and
the number of the Newton iterations in parentheses. We note that
the convergence rate is problem-data dependent.
From Table 1, we see that for a 4000-by-4000 matrix,
the algorithm
reached 7.19/23.12=31% efficiency with respect to PUMMA matrix multiplication,
and 7.19/8.70=82% efficiency with respect to the underlying ScaLAPACK 1.0 (beta)
matrix inversion subroutine.
As our performance model shows, and tables 9, 10,
11, 12, and 14 confirm,
efficiency will continue to improve as the matrix size  increases.
Our performance model is explained in section 4.
Figure 3 shows the performance of Algorithm 1
on the Intel Delta system as a function of
matrix size for different numbers of processors.
increases.
Our performance model is explained in section 4.
Figure 3 shows the performance of Algorithm 1
on the Intel Delta system as a function of
matrix size for different numbers of processors.

Table 1: Backward accuracy, timing in seconds and megaflops of Algorithm 1 on a 256 node Intel Touchstone Delta system.

Figure 3: Performance of Algorithm 1 on the
Intel Delta system as a function of matrix size for different
numbers of processors.
Table 2 gives details of the total CPU timing of the Newton iteration based algorithm, summarized in Table 1). It is clear that the Newton iteration (sign function) is most expensive, and takes about 90% of the total running time.
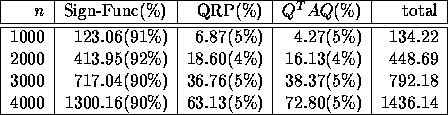
Table 2: Performance Profile on a 256 processor Intel Touchstone Delta system
(time in seconds)
To compare with the standard sequential algorithm,
we also ran the LAPACK driver routine DGEES for computing the Schur
decomposition (with reordering of eigenvalues) on one i860 processor.
It took 592 seconds for a matrix of order 600, or 9.1 megaflops/second.
Assuming that the time scales like 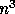 ,
we can predict that for a matrix of order 4000, if
the matrix were able to fit on a single node,
then DGEES would take 175,000 seconds (48 hours) to compute the desired
spectral decomposition. In contrast, Algorithm 1 would only take 1,436 seconds (24 minutes). This is about
120 times faster! However, we should note that DGEES actually
computes a complete Schur decomposition with the necessary reordering
of the spectrum. Algorithm 1 only decomposes the spectrum along the pure imaginary
axis. In some applications, this may be what the users want. If
the decomposition along a finer region or a complete Schur decomposition
is desired, then the cost of the Newton iteration based algorithms will be
increased, though it is likely that the first step just described will
take most of the time [13].
,
we can predict that for a matrix of order 4000, if
the matrix were able to fit on a single node,
then DGEES would take 175,000 seconds (48 hours) to compute the desired
spectral decomposition. In contrast, Algorithm 1 would only take 1,436 seconds (24 minutes). This is about
120 times faster! However, we should note that DGEES actually
computes a complete Schur decomposition with the necessary reordering
of the spectrum. Algorithm 1 only decomposes the spectrum along the pure imaginary
axis. In some applications, this may be what the users want. If
the decomposition along a finer region or a complete Schur decomposition
is desired, then the cost of the Newton iteration based algorithms will be
increased, though it is likely that the first step just described will
take most of the time [13].