The classic quicksort algorithm is a divide-and-conquer sorting method ([Hoare:62a], [Knuth:73a] pp.118-23). As such, it would seem to be amenable to a concurrent implementation, and with a slight modification (actually an improvement of the standard algorithm) this turns out to be the case.
The standard algorithm begins by picking some item from the list and using this as the splitting key. A loop is entered which takes the splitting key and finds the point in the list where this item will ultimately end up once the sort is completed. This is the first splitting point. While this is being done, all items in the list which are less than the splitting key are placed on the low side of the splitting point, and all higher items are placed on the high side. This completes the first divide. The list has now been broken into two independent lists, each of which still needs to be sorted.
The essential idea of the concurrent (hypercube) quicksort is the same. The first splitting key is chosen (a global step to be described below) and then the entire list is split, in parallel, between two halves of the hypercube. All items higher than the splitting key are sent in one direction in the hypercube, and all items less are sent the other way. The procedure is then called recursively, splitting each of the subcubes' lists further. As in Shellsort, the ring-based labelling of the hypercube is used to define global order. Once d splits occur, there remain no further interprocessor splits to do, and the algorithm continues by switching to the internal quicksort mentioned earlier. This is illustrated in Figure 12.33.
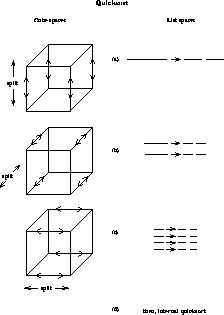
Figure 12.33: An Illustration of the Parallel Quicksort
So far, we have concentrated on standard quicksort. For quicksort to work well, even on sequential machines, it is essential that the splitting points land somewhere near the median of the list. If this isn't true, quicksort behaves poorly, the usual example being the quadratic time that standard quicksort takes on almost-sorted lists. To counteract this, it is a good idea to choose the splitting keys with some care so as to make evenhanded splits of the list.
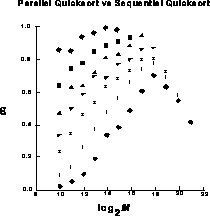
Figure: Efficiency Data for the Parallel Quicksort described in the
Text. The curves are labelled as in Figure 12.30 and
plotted against the logarithm of the number of items to be sorted.
This becomes much more important on the concurrent computer. In this case,
if the splits are done haphazardly, not only will an excessive number of
operations be necessary, but large load imbalances will also occur.
Therefore, in the concurrent algorithm, the splitting keys are chosen with
some care. One reasonable way to do this is to randomly sample a subset of
the entire list (giving an estimate of the true distribution of the list) and
then pick splitting keys based upon this sample. To save time, all 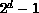 splitting keys are found at once. This modified algorithm should perhaps be
called samplesort and consists of the following steps:
splitting keys are found at once. This modified algorithm should perhaps be
called samplesort and consists of the following steps:
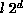 items using the parallel shellsort;
items using the parallel shellsort;
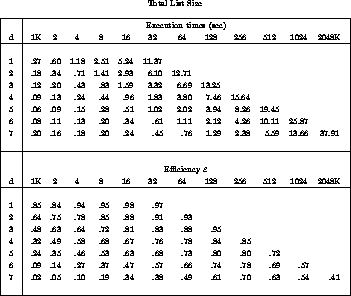
Times and efficiencies for the parallel quicksort algorithm are shown in Table 12.4. The efficiencies are also plotted in Figure 12.34. In some cases, the parallel quicksort outperforms the already high performance of the parallel shellsort discussed earlier. There are two main sources of inefficiency in this algorithm. The first is a result of the time wasted sorting the sample. The second is due to remaining load imbalance in the splitting phases. By varying the sample size l, we achieve a trade-off between these two sources of inefficiency. Chapter 18 of [Fox:88a] contains more details regarding the choice of l and other ways to compute splitting points.
Before closing, it may be noted that there exists another way of thinking
about the parallel quicksort/samplesort algorithm. It can be regarded as a
bucketsort, in which each processor of the hypercube comprises one bucket.
In the splitting phase, one attempts to determine reasonable limits for the
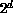 buckets so that approximately equal numbers of items will end up in each
bucket. The splitting process can be thought of as an optimal routing scheme
on the hypercube which brings each item to its correct bucket. So, our
version of quicksort is also a bucketsort in which the bucket limits are
chosen dynamically to match the properties of the particular input list.
buckets so that approximately equal numbers of items will end up in each
bucket. The splitting process can be thought of as an optimal routing scheme
on the hypercube which brings each item to its correct bucket. So, our
version of quicksort is also a bucketsort in which the bucket limits are
chosen dynamically to match the properties of the particular input list.
The sorting work began as a collaboration between Steve Otto and summer students Ed Felten and Scott Karlin. Ed Felten invented the parallel Shellsort; Felten and Otto developed the parallel Quicksort.