There are several options at the user's disposal that allow PVM to optimize communication on a given virtual machine. Communication across nodes of an MPP and across processors of a shared memory multiprocessor are automatically optimized by using the native communication calls and shared memory respectively. The following discussion restricts itself to performance improvements across a network of hosts.
PVM uses UDP and TCP [] sockets to move data over networks.
UDP is a connectionless datagram protocol packet delivery is
not guaranteed. TCP requires a connection between processes
and implements sophistocated retry algorithms to ensure data delivery.
In PVM the default, scalable transfer method is for a task to send
the message to the local PVM daemon. The local daemon transfers
the message to the remote daemon using UDP, finally the remote daemon
transfers the message to the remote task when requested by a pvm_recv().
Since UDP does not guarentee packet delivery, we implement a lightweight
protocol to assure full message delivery between daemons.
PVM 3.3 improves the performance of this route by using
Unix domain sockets between tasks and the local PVM daemon.
Measurements showed this improved the task to daemon latency
and bandwidth by a factor of 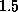 to
to 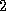 .
.
A less scalable but faster transfer method is available in PVM.
By calling pvm_setopt(PvmRoute, PvmRouteDirect),
PVM will set up a direct task to task TCP link between the calling task
and any other task it sends to. The initial TCP set up time is large
but all subsequent messages between the same two tasks have been
measured to be 2-3x faster than the default route.
The primary drawback of this method is that each TCP socket
consumes one file descriptor (fd).
Thus there is the potential to need 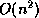 file descriptors,
where
file descriptors,
where  is the number of tasks in the virtual machine.
Since direct routing only involves a single call at the top of a PVM program,
it is reasonable to try PvmRouteDirect to see if it
improves the performance of an application.
is the number of tasks in the virtual machine.
Since direct routing only involves a single call at the top of a PVM program,
it is reasonable to try PvmRouteDirect to see if it
improves the performance of an application.
There are two encoding options available in PVM 3.3 whose purpose is to boost communication performance. Since a message may be sent to several destinations, by default PVM will encode it for heterogeneous delivery during packing. If the message will only be sent to hosts with compatible data format, then the user can tell PVM to skip the encoding step. This is done by calling pvm_initsend(PvmDataRaw).
The second encoding option is pvm_initsend(PvmDataInplace). When PvmDataInplace is specified the data is never packed into a buffer. Instead it is left ``inplace'' in user memory until pvm_send() is called and then copied directly from user memory to the network. During the packing steps PVM simply keeps track of where and how much data is specified. This option reduces the pack time dramatically. It also has the benefit of reducing memory requirements since the send buffer no longer holds a copy of the message.
One must exercise care when using PvmDataInPlace. If the user's data is modified after the pack call but before the send call then the modified data will be sent, not the data originally specified in the pack call. This behavior is different from using the other pvm_initsend() modes where the data is copied at pack time.
As mentioned earlier, pvm_psend() was implemented for performance reasons. As such it uses PvmDataInplace. This coupled with only one call overhead makes pvm_psend(), when combined with PvmRouteDirect, the fastest method to send data in PVM 3.3.
Figure 1 plots bandwidth versus message size for various packing and routing options. The lines marked dir and hop indicate direct and default routing respectively. (Hop because the default messages make extra hops through the PVM daemons.) Inplace packing and unpacking is indicated by inp. Lines marked with raw show the case where no data conversion was done while xdr indicates messages were converted into the XDR format before sending and from the XDR format after recieving them at the destination. The tests were run on Dec Alpha workstations connected by FDDI. This experiment shows that the avoidance of data copying and conversion along with direct routing allows PVM to achieve good end to end performance for large messages. The peak bandwidth of FDDI is 100Mbit/s or 12.5 MByte/s. In the best case we achieve approximately 8 MByte/second bandwidth for large messages, 64% of the network's peak bandwidth. Note that these times include both packing the message at the sender and unpacking the message buffer at the receiver. The advantage of inplace packing for large messages is clearly shown. The high cost of using heterogeneous data conversion can also bee seen from the XDR bandwidth curves.
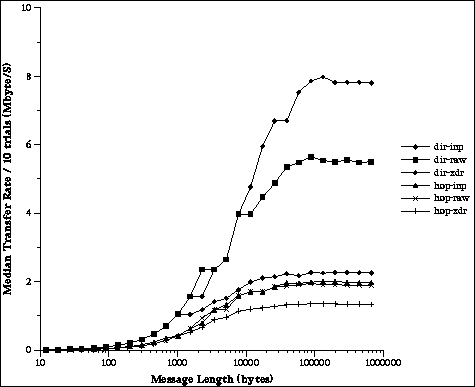
Figure 1: PVM message bandwidth versus size.
Figure 2 shows latency measurements for the same experiment. We see that latency is much smaller when using directly connected message routing. Both raw and inplace packing achieve the lowest latency with inplace being slightly better for large messages.
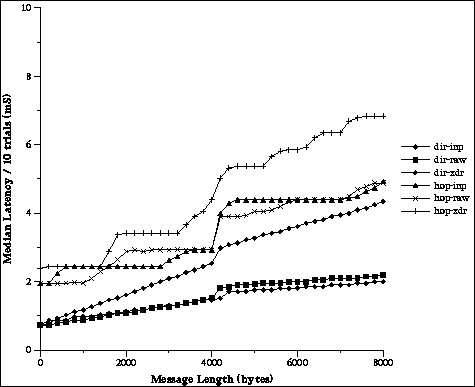
Figure 2: PVM message latency versus size.