In general, PVM programs consist of tasks that communicate via messages. A task is a basic unit of computation in PVM, a Unix process for instance. From the first release of PVM 3.0 until the recent release of PVM 3.3 there has been only a single routine to send a message to another task. In PVM 3.3 there is an additional routine for sending and two new routines for receiving messages. In this section we describe the point to point communication routines in PVM 3.3 and show how to enhance the performance of applications by using these routines.
The philosophy of PVM has always been to keep the user interface simple and easy to understand, letting PVM do all the hard work underneath in order to improve performance. For example, when a user sends a message, he would like the data to arrive instantly at the destination. In reality this can never happen. There is always some startup latency plus the time it takes to actually move the data. These overheads can not be avoided but they can be masked by other work. Some message passing interfaces, such as MPI [4], go to great lengths to supply many variants of `send' in order to allow the user several ways to explicitly manage the masking of the send overheads. This is good if the goal is to supply the ability to achieve the ultimate peak performance of a large multiprocessor, but it requires an expert in parallel programming to achieve this peak. The vast majority of scientists and engineers who use parallel programming are not experts in it. They use the basic send and receive primitives in their codes.
The PVM communication model assumes that any task can send a message to any other PVM task, and that there is no limit to the size or number of such messages. While all hosts have physical memory limitations that restrict potential buffer space, the communication model does not restrict itself to a particular machine's limitations. It assumes sufficient memory is available. PVM allocates buffer space dynamically so the size or volume of messages that can arrive at a single host at the same time is only limited by the available memory on the machine.
The PVM communication model provides asynchronous blocking send, asynchronous blocking receive, and non-blocking receive functions. In our terminology, a blocking send returns as soon as the send buffer is free for reuse, and an asynchronous send does not depend on the receiver calling a matching receive before the send can return. A non-blocking receive immediately returns with either the data or a flag that the data has not arrived, while a blocking receive returns only when the data is in the receive buffer. Wildcards can be specified in the receive for the source and message type, allowing either or both of these contexts to be ignored. A routine can be called to return information about received messages.
The PVM model guarantees that message order is preserved between two tasks. If task 1 sends message A to task 2, then task 1 sends message B to task 2, message A will arrive at task 2 before message B. Moreover, if both messages arrive before task 2 does a receive, then a wildcard receive will always return message A. The programmer can also specify a specific message type, called a tag. When a tag is specified, PVM will return the first incoming message with the requested tag.
Until PVM 3.3, sending a message with PVM required three function calls. First, a send buffer is initialized by a call to pvm_initsend(). This step also has the effect of clearing the previous send buffer, if any. Second, the message must be ``packed'' into this buffer using any number and combination of pvm_pk*() routines. At this step PVM takes care of any data encoding needed for heterogeneity and builds the buffer in fragments (required by the network protocols) so the overhead of fragmenting a large buffer during transmission is avoided. Third, the completed message is sent to another process by calling the pvm_send() routine.
There are several advantages of having this three step method. The method allows the user to pack a message with several different pieces of data. For example, a message may contain a floating point array and an integer defining its size. Or a single message may contain an entire `structure' including integer arrays, character strings, and floating point arrays. Why is this important? Packing a message is fast relative to transferring the data over a network, although this is beginning to change as networks become faster. By being able to combine several different pieces of information into a single message, the user can decrease the number of sends in an algorithm. This eliminates the startup latency for all the sends that are saved. Another important advantage is the avoidance of matching `structures' back up on the receiver. Let's illustrate with a contrived example. Assume we restrict messages to a single data type and the data structure to be sent is a sparse floating point array without the zeros, an integer specifying the number of floats, and an integer array of indices corresponding to the matrix location of each floating point value. Now assume one task has to receive a few structures of this kind from several other tasks. Since the order that the floating point and integer messages arrive at the receiver is arbitrary, because messages may come from different sources, several structures could be interleaved in the message queue. The receiver then is responsible for searching the queue and properly reassembling the structures. This search and reconstruct phase is not needed when the various data types are combined into the same message. The philosophy of PVM is to be simple to use. It is easy for a non-expert to understand the concept of packing up a structure of data, sending it, and unpacking the message at the receiver.
Another advantage of the three step method is the need to encode and fragment the message only once. In PVM once the message is packed, it can be sent to several different destinations. There are many parallel scientific applications were a task must send its data to its `neighbors'. In cases like this, PVM eliminates the overhead of packing each send separately. PVM also takes advantage of packing only once when a user broadcasts a message.
The separate buffer initialization step also has the advantage that the user can append data onto a buffer that is already sent. Since PVM doesn't clear the buffer until the next pvm_initsend() call, a task can pack and send a message to one destination then append to that message and send it to another destination and so on. There are certain ring algorithms that benefit from such a capability, but the ability to append to messages is not commonly used.
Although there are several advantages to the three step send, there are many parallel algorithms that just need to send one array of a given data type to one destination. Because this type of message is so common, it would be useful to avoid the the three step send in this case. In PVM 3.3 this is now possible by using the new function pvm_psend(). pvm_psend() combines the initialize, pack, and send steps into a single call with an orientation towards performance.
The request to have pvm_psend() and its compliment pvm_precv() initially came from MPP vendors who were developing optimized PVM versions for their systems. On MPP systems vendors try to supply the smallest possible latency. The overhead of three subroutine calls is large relative to the raw communication times on MPP systems. The addition of pvm_psend/pvm_precv to PVM has significantly boosted the performance of point-to-point PVM communication on MPP machines. For example, Table 1 shows that the message passing passing performance on the Intel Paragon using pvm_psend/pvm_precv is only 5-8% larger than the native calls csend/crecv. This low overhead on the Paragon can be attributed to the close mapping between the functionality of the PVM calls and Intel's native calls. On the Cray T3D, PVM is the native message passing interface. The latency for pvm_psend() on the T3D is only 18 microseconds and the bandwidth is over 45 Mbytes/sec.
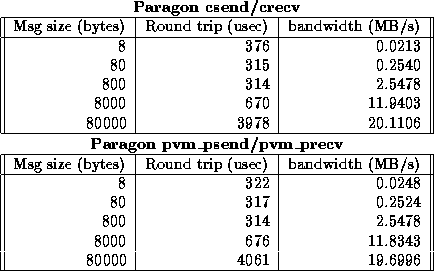
Table 1: Paragon node to node round trip comparison of PVM and native calls.
PVM contains several methods of receiving messages at a task. There is no function matching requirement in PVM, for example it is not necessary that a pvm_psend be matched with a pvm_precv. Any of the following routines can be called for any incoming message no matter how it was sent (or multicast).
As a new function in PVM 3.3, PVM supplies a timeout version of receive. Consider the case where a message is never going to arrive (due to error or failure). The routine pvm_recv would block forever. There are times when the user wants to give up after waiting for a fixed amount of time. The routine pvm_trecv allows the user to specify a timeout period. If the timeout period is set very large then pvm_trecv acts like pvm_recv. If the timeout period is set to zero then pvm_trecv acts like pvm_nrecv. Thus, pvm_trecv fills the gap between the blocking and nonblocking receive functions.