




An item in the two-dimensional track file is described by an eight-component state vector
where the component vectors on the RHS of Equation 18.6 are four-element kinematic state vectors as defined for Equation 18.1, referred to the standard measurement axes:
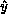 :
:
 :
:
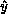 is noninertial, so that the state in
Equation 18.6 has substantial ``contaminations'' from motion of
the sensor.
is noninertial, so that the state in
Equation 18.6 has substantial ``contaminations'' from motion of
the sensor.
In principle, each track described by Equation 18.6 has an associated covariance matrix with 36 independent elements. In order to reduce the storage and CPU resource requirements of two-dimensional tracking, a simplifying assumption is made. The measurement error matrix for a two-dimensional datum
is taken to have the simple form
with the same effective value 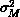 used to describe the
measurement variance for each projection, and no correlation of the
measurement errors. The assumption in
Equations 18.7 and 18.8 is reasonable,
provided the effective measurement error
used to describe the
measurement variance for each projection, and no correlation of the
measurement errors. The assumption in
Equations 18.7 and 18.8 is reasonable,
provided the effective measurement error 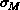 is made large enough, and
reduces the number of independent components in the covariance matrix from 36
to 10.
is made large enough, and
reduces the number of independent components in the covariance matrix from 36
to 10.
The central task of the two-dimensional track extension module is to
find all plausible track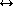 hit associations, subject to a
set of criteria which define ``plausible.'' The primary association
criterion is based on the track association score
hit associations, subject to a
set of criteria which define ``plausible.'' The primary association
criterion is based on the track association score
where 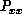 is the variance of the prediced data position along a reference
axis and
is the variance of the prediced data position along a reference
axis and
is the difference between the actual data value and that predicted by Equation 18.6 for the time of the datum. Equation 18.9 is simply a dimensionless measure of the size of the mismatch in Equation 18.10, normalized by the expected prediction error.
The first step in limiting Track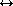 Hit associations is a simple
cut
Hit associations is a simple
cut 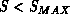 on the association score of Equation 18.9.
For the dense, multitarget environments used in Sim89, this simple cut is
not sufficiently restrictive, and a variety of additional heuristic cuts are
made. The most important of these are
on the association score of Equation 18.9.
For the dense, multitarget environments used in Sim89, this simple cut is
not sufficiently restrictive, and a variety of additional heuristic cuts are
made. The most important of these are
The actual track scoring cut is a bit more complicated than the preceding
paragraph implies. Let 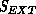 denote the nominal extension score of
Equation 18.9. In addition, define a cumulative association
score
denote the nominal extension score of
Equation 18.9. In addition, define a cumulative association
score 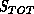 which is updated on associations in a fading memory fashion
which is updated on associations in a fading memory fashion
with (typically) 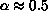 . An extension is accepted only if
. An extension is accepted only if
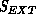 is below some nominal cutoff (typically 3-4
is below some nominal cutoff (typically 3-4 ) and
) and
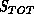 is below a more restrictive cut (2-3
is below a more restrictive cut (2-3 ). This second cut
prevents creation of poor tracks with barely acceptable extension scores at
each step.
). This second cut
prevents creation of poor tracks with barely acceptable extension scores at
each step.
The preceding rules for Track Hit associations define the
basic two-dimensional track extension formalism. There are, however, two additional
problems which must be addressed:
Hit associations define the
basic two-dimensional track extension formalism. There are, however, two additional
problems which must be addressed:
In regard to the first problem, two entries in the track file are said to
be equivalent if they involve the same associated data points
over the past four scans. If an equivalent track pair is found in the track
file, the track with a higher cumulative score 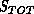 is simply deleted.
The natural mechanism for track deletion in a track-splitting model is based
on the track's data association history. If no data items give acceptable
association scores over some preset number of scans (typically 0-2), the
track is simply discarded.
is simply deleted.
The natural mechanism for track deletion in a track-splitting model is based
on the track's data association history. If no data items give acceptable
association scores over some preset number of scans (typically 0-2), the
track is simply discarded.
The equivalent-track merging and poor track deletion mechanisms are not
sufficient to prevent track file ``explosions'' in truly dense environments.
A final track-limiting mechanism is simply a hard cutoff on the number of
tracks maintained for any item in the data set (this cut is typically
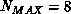 ). If more than
). If more than 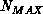 tracks give acceptable association
scores to a particular datum, only the
tracks give acceptable association
scores to a particular datum, only the 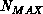 pairings with the lowest
total association scores
pairings with the lowest
total association scores 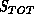 are kept.
are kept.
The complexity of the track extension algorithm is nominally
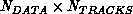 for
for 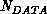 new data items and
new data items and 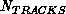 existing tracks. This
existing tracks. This 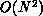 computational burden is easily reduced
to something closer to
computational burden is easily reduced
to something closer to 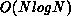 by sorting both the incoming data and the
predicted data values for existing tracks.
by sorting both the incoming data and the
predicted data values for existing tracks.





