




The original structure of multiple data-parallel function emulations executing concurrently was left intact by this evolution. The supporting services and means of synchronizing the various activities have evolved considerably, however.
The execution of the simulation as shown in Figure 18.9 is synchronized rather simply. Refer now to Figure 18.13. By the structure of the desired activities, sensor data are sent to the Trackers, their tracks are sent to the Battle Planner, and the battle plans are returned to the Environment Generator (which calculates the effects of any defensive actions taken). The exchange of mono tracks shown is a communication internal to the Tracker's two subcubes.
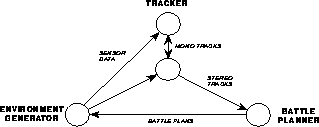
Figure: The Simulation of Figure 18.9 is Controlled
by a Pipeline Synchronization
The simulation initiates by having each module forward its data to the next unit in the pipeline and then read its input data as initialization for the first set of computations. At initialization, all messages are null except the sensor messages from the Environment Generator. In the first computation cycle, only the Tracker is active; the Battle Planner has no tracks. After the tracker completes its initial sensor data processing (described in detail later in the chapter), the resulting tracks are forwarded to the Battle Planner, which starts computing its first battle plan while the Tracker is working on the second set of sensor data-a computational pipeline, or round, has been established. When an element finishes with a given work segment, the results are forwarded and that element then waits if necessary for the data that initiates the next work segment. Convenient, effective, but hardly of the generality of, say, Time Warp (described in Section 15.3) as a means of concurrency control.
Yet a full implementation of Time Warp is not necessarily required here even in the most general circumstances. Remember that Time Warp implements a general but pure discrete event simulation. Its objective-speedup-is achieved by capitalizing on the functional parallelism inherent in all the multiple objects, analogous to the multiple functions being described here. It permits the concurrent execution of the needed procedures and ensures a correct simulation via rollback when the inevitable time accidents occur. In the type of simulation discussed here, not only is speedup often not the goal, but when it is, it is largely obtained via the data parallelism of each function and load-balanced by the judicious assignment of the correct number of processors to each. The speedup due to functional parallelism can be small and good performance can still result. A means of assuring a correct simulation, however, is crucial.
We have experimented with several synchronization schemes that will ensure this correctness even when the simulation is of a generality illustrated by Figure 18.11. The most straightforward of these is termed time buckets and is useful whenever one can structure a simulation where activities taking place in one time interval, or bucket, can only have effects later on in the next or succeeding time buckets.
The initial implementation of the time bucket approach was in conjunction with an SDS communications simulation, one that sought to treat in higher fidelity the communications activities implicit in Figure 18.11. In this simulation, the emulators of the communications processors aboard each satellite and the participating ground stations were distributed across the nodes of the Mark III hypercube. In the most primitive implementation, each node would emulate the role of a single satellite's comm processor; messages would be physically passed via the hypercube comm channels and a rather complete emulation would result.
Since the correspondence to the real world is not perfect-actual hypercube comm delays are not equal to the satellite-to-satellite light time delays, for example, this emulation must be controlled and synchronized just like a conventional discrete-event parallel simulation if time accidents are not to occur and invalidate the results. Figure 18.14 shows the use of the time bucket approach for synchronization in this situation. The key is to note that, because of the geometries involved there is a minimum light time delay between any two satellites. If the processing is done in time steps-time buckets, if you will-of less than this delay, it is possible to ensure that accidents will never occur.
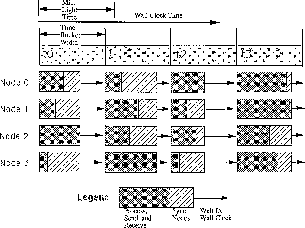
Figure 18.14: The Time Bucket Approach to Synchronization Control
Referring to Figure 18.14, assume each of the processors is
released at time 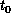 and is free to process all messages in its input queue
up to and including the time bucket's duration without regard to any
coordination of the progress of simulation time in the other nodes. Since
the minimum light time delay is longer than this bucket, it is not possible
for a remote node to send a message and have it received (in simulation time)
interior to the free processing time; no accidents can occur. Each node
then processes all its events up to a simulation time advance of one time
bucket. It waits until all processors have reached the same point and all
messages-new events from outside nodes-have been received and placed
properly in their local event queues. When all processors have finished, the
next time bucket can be entered.
and is free to process all messages in its input queue
up to and including the time bucket's duration without regard to any
coordination of the progress of simulation time in the other nodes. Since
the minimum light time delay is longer than this bucket, it is not possible
for a remote node to send a message and have it received (in simulation time)
interior to the free processing time; no accidents can occur. Each node
then processes all its events up to a simulation time advance of one time
bucket. It waits until all processors have reached the same point and all
messages-new events from outside nodes-have been received and placed
properly in their local event queues. When all processors have finished, the
next time bucket can be entered.
The maximum rate that simulation time can advance is, of course, determined by the slowest node to complete in each time bucket. If proceeding is desired, not as rapidly as possible but in real time (i.e., maintaining a close one-to-one correspondence between elapsed wall clock and simulation time), the nodes can additionally wait for the wall clock to catch up to simulation time before proceeding; this behavior is illustrated in Figure 18.4.
While described as a communication simulation, this is a rather general
technique. It can be used whenever the simulation modules can reasonably
obey the constraint that they not schedule events shorter than 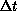 into the future for objects external to the local node. It can work
efficiently whenever the density of events/processor is significantly greater
than unity for this same
into the future for objects external to the local node. It can work
efficiently whenever the density of events/processor is significantly greater
than unity for this same 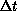 . A useful view of this technique is that
the simulation is fully parallel and event-driven interior to a time bucket,
but is controlled by an implicit global controller and is a time-stepped
simulation with respect to coarser time resolutions.
. A useful view of this technique is that
the simulation is fully parallel and event-driven interior to a time bucket,
but is controlled by an implicit global controller and is a time-stepped
simulation with respect to coarser time resolutions.
Implementation varies. The communication simulation just described was hosted on the Mark III and took advantage of the global lines to coordinate the processor release times. In more general circumstances where globals are not available, an alternative time service [Li:91a] has been implemented and is currently used for a network-based parallel Strategic Air Defense simulation.
Where a fixed time step does not give adequate results, an alternate
technique implementing an adaptive  has been proposed and
investigated [Steinman:91a]. This technique, termed breathing time
buckets, is notionally diagrammed in Figure 18.15. Pictured there
are the local event queues for two nodes. These event queues are complete
and ordered at the assumed synchronized start of cycle simulation time. The
object of the initial processing is to determine a ``global event horizon''
which is defined as the time of the earliest new event that will be generated
by the subsequent processing. Current events prior to that time may be
processed in all the nodes without fear of time accidents. This time is
determined by having each node optimistically process its own local events,
but withhold the sending of messages, until it has reached a simulation time
where the next event to be processed is a ``new'' event. The time reached is
called the ``local event horizon.'' Once every node has determined its local
horizon, a global minimum is determined and equated to the global event
horizon. All nodes then roll back their local objects
to that simulation time (easy since no messages have been sent) send
the messages that are valid, and commit to the event processing up to
that point.
has been proposed and
investigated [Steinman:91a]. This technique, termed breathing time
buckets, is notionally diagrammed in Figure 18.15. Pictured there
are the local event queues for two nodes. These event queues are complete
and ordered at the assumed synchronized start of cycle simulation time. The
object of the initial processing is to determine a ``global event horizon''
which is defined as the time of the earliest new event that will be generated
by the subsequent processing. Current events prior to that time may be
processed in all the nodes without fear of time accidents. This time is
determined by having each node optimistically process its own local events,
but withhold the sending of messages, until it has reached a simulation time
where the next event to be processed is a ``new'' event. The time reached is
called the ``local event horizon.'' Once every node has determined its local
horizon, a global minimum is determined and equated to the global event
horizon. All nodes then roll back their local objects
to that simulation time (easy since no messages have been sent) send
the messages that are valid, and commit to the event processing up to
that point.
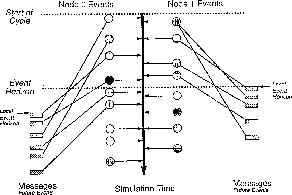
Figure 18.15: Breathing Time Buckets as a Means of Synchronization Control
In implementation, there are many refinements and extensions of these basic ideas in order to optimize performance, but this is the fundamental construct. It is proving to be relatively easily implemented, gives good performance in a variety of circumstances, and has even outperformed Time Warp in some cases [Steinman:92a].
Synchronization control is but one issue, albeit the most widely discussed and debated, in building a general framework to support this class of simulation. Viewed from the perspective of cooperative high performance computing, the Simulation Framework can be seen as services needed by the individual applications programmer, but not provided by the network or parallel computer operating system. Providing support for: