




The Connection Machine Model CM-2 is also
very well suited for large scale simulations of QCD. The CM-2 is a
distributed-memory, single-instruction, multiple-data (SIMD), massively
parallel processor comprising up to 65536 (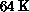 ) processors
[Hillis:85a;87a]. Each processor
consists of an arithmetic-logic unit (ALU),
) processors
[Hillis:85a;87a]. Each processor
consists of an arithmetic-logic unit (ALU), 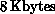 or
or 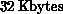 of random-access memory (RAM), and a router interface to
perform communications among the processors. There are 16 processors
and a router per custom VLSI chip, with the chips
interconnected as a 12-dimensional hypercube. Communications among
processors within a chip work essentially like a crossbar
interconnect. The router can do general communications, but only local
communication is required for QCD, so we use the fast nearest-neighbor
communication software called NEWS. The processors deal with one bit
at a time. Therefore, the ALU can compute any two Boolean functions as
output from three inputs, and all datapaths are one bit wide. In the
current version of the Connection Machine (the CM-2), groups of 32
processors (two chips) share a 32-bit (or 64-bit) Weitek floating-point
chip, and a transposer chip, which changes 32 bits stored bit-serially
within 32 processors into 32 32-bit words for the Weitek, and vice
versa.
of random-access memory (RAM), and a router interface to
perform communications among the processors. There are 16 processors
and a router per custom VLSI chip, with the chips
interconnected as a 12-dimensional hypercube. Communications among
processors within a chip work essentially like a crossbar
interconnect. The router can do general communications, but only local
communication is required for QCD, so we use the fast nearest-neighbor
communication software called NEWS. The processors deal with one bit
at a time. Therefore, the ALU can compute any two Boolean functions as
output from three inputs, and all datapaths are one bit wide. In the
current version of the Connection Machine (the CM-2), groups of 32
processors (two chips) share a 32-bit (or 64-bit) Weitek floating-point
chip, and a transposer chip, which changes 32 bits stored bit-serially
within 32 processors into 32 32-bit words for the Weitek, and vice
versa.
The high-level languages on the CM, such as *Lisp and CM-Fortran,
compile into an assembly language called Parallel Instruction Set
(Paris). Paris regards the 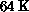 bit-serial processors as the
fundamental units in the machine. However, floating-point computations
are not very efficient in the Paris model. This is because in Paris,
32-bit floating-point numbers are stored ``fieldwise''; that is,
successive bits of the word are stored at successive memory locations
of each processor's memory. However, 32 processors share one Weitek
chip, which deals with words stored ``slicewise''-that is, across the
processors, one bit in each. Therefore, to do a floating-point
operation, Paris loads in the fieldwise operands, transposes them
slicewise for the Weitek (using the transposer chip), does the
operation, and transposes the slicewise result back to fieldwise for
memory storage. Moreover, every operation in Paris is an
atomic process; that is, two operands are brought from
memory and one result is stored back to memory, so no use is made of
the Weitek registers for intermediate results. Hence, to improve the
performance of the Weiteks, a new assembly language called CM
Instruction Set (CMIS) has been written, which models the local
architectural features much better. In fact, CMIS ignores the
bit-serial processors and thinks of the machine in terms of the Weitek
chips. Thus, data can be stored slicewise, eliminating all the
transposing back and forth. CMIS allows effective use of the Weitek
registers, creating a memory hierarchy, which, combined with the
internal buses of the Weiteks, offers increased
bandwidth for data motion.
bit-serial processors as the
fundamental units in the machine. However, floating-point computations
are not very efficient in the Paris model. This is because in Paris,
32-bit floating-point numbers are stored ``fieldwise''; that is,
successive bits of the word are stored at successive memory locations
of each processor's memory. However, 32 processors share one Weitek
chip, which deals with words stored ``slicewise''-that is, across the
processors, one bit in each. Therefore, to do a floating-point
operation, Paris loads in the fieldwise operands, transposes them
slicewise for the Weitek (using the transposer chip), does the
operation, and transposes the slicewise result back to fieldwise for
memory storage. Moreover, every operation in Paris is an
atomic process; that is, two operands are brought from
memory and one result is stored back to memory, so no use is made of
the Weitek registers for intermediate results. Hence, to improve the
performance of the Weiteks, a new assembly language called CM
Instruction Set (CMIS) has been written, which models the local
architectural features much better. In fact, CMIS ignores the
bit-serial processors and thinks of the machine in terms of the Weitek
chips. Thus, data can be stored slicewise, eliminating all the
transposing back and forth. CMIS allows effective use of the Weitek
registers, creating a memory hierarchy, which, combined with the
internal buses of the Weiteks, offers increased
bandwidth for data motion.
When the arithmetic part of the program is rewritten in CMIS (just as on the Mark IIIfp when it was rewritten in assembly code), the communications become a bottleneck. Therefore, we need also to speed up the communication part of the code. On the CM-2, this is done using the ``bi-directional multi-wire NEWS'' system. As explained above, the CM chips (each containing 16 processors) are interconnected in a 12-dimensional hypercube. However, since there are two CM chips for each Weitek floating-point chip, the floating-point hardware is effectively wired together as an 11-dimensional hypercube, with two wires in each direction. This makes it feasible to do simultaneous communications in both directions of all four space-time directions in QCD-bidirectional multiwire NEWS-thereby reducing the communication time by a factor of eight. Moreover, the data rearrangement necessary to make use of this multiwire NEWS further speeds up the CMIS part of the code by a factor of two.
In 1990-1992, the Connection Machine was
the most powerful commercial QCD machine available: the ``Los Alamos
collaboration'' ran full QCD at a sustained rate of 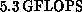 on a
on a 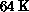 CM-2 [Brickner:91a]. As was the case for the
Mark IIIfp hypercube, in order to obtain this performance, one must
resort to writing assembly code for the Weitek chips and for
the communication. Our original code, written entirely in the CM-2
version of *Lisp, achieved around
CM-2 [Brickner:91a]. As was the case for the
Mark IIIfp hypercube, in order to obtain this performance, one must
resort to writing assembly code for the Weitek chips and for
the communication. Our original code, written entirely in the CM-2
version of *Lisp, achieved around 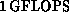 [Baillie:89e].
As shown in Table 4.5, this code spends 34 percent of its
time doing communication. When we rewrote the most computationally
intensive part in the assembly language CMIS, this rose to 54 percent.
Then when we also made use of ``multi-wire NEWS'' (to reduce the
communication time by a factor of eight), it fell to 30 percent. The
Intel Delta and Paragon, as well as Thinking Machines CM-5, passed the
CM-2 performance levels in 1993, but here optimization is not yet
complete [Gupta:93a].
[Baillie:89e].
As shown in Table 4.5, this code spends 34 percent of its
time doing communication. When we rewrote the most computationally
intensive part in the assembly language CMIS, this rose to 54 percent.
Then when we also made use of ``multi-wire NEWS'' (to reduce the
communication time by a factor of eight), it fell to 30 percent. The
Intel Delta and Paragon, as well as Thinking Machines CM-5, passed the
CM-2 performance levels in 1993, but here optimization is not yet
complete [Gupta:93a].
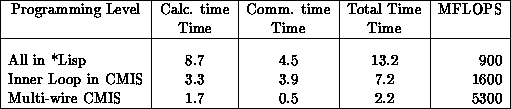
Table 4.5: Fermion Update Time (sec) on 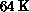 Connection Machine for
Various Levels of Programming
Connection Machine for
Various Levels of Programming