




Lattice QCD is truly a ``grand challenge'' computing problem. It has been estimated that it will take on the order of a TeraFLOP-year of dedicated computing to obtain believable results for the hadron mass spectrum in the quenched approximation, and adding dynamical fermions will involve many orders of magnitude more operations. Where is the computer power needed for QCD going to come from? Today, the biggest resources of computer time for research are the conventional supercomputers at the NSF and DOE centers. These centers are continually expanding their support for lattice gauge theory, but it may not be long before they are overtaken by several dedicated efforts involving concurrent computers. It is a revealing fact that the development of most high-performance parallel computers-the Caltech Cosmic Cube, the Columbia Machine, IBM's GF11, APE in Rome, the Fermilab Machine and the PAX machines in Japan-was actually motivated by the desire to simulate lattice QCD [Christ:91a], [Weingarten:92a].
As described already, Caltech built the first hypercube computer, the
Cosmic Cube or Mark I, in 1983. It had 64 nodes,
each of which was an Intel 8086/87 microprocessor with 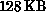 of
memory, giving a total of about
of
memory, giving a total of about 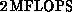 (measured for QCD).
This was quickly upgraded to the Mark II hypercube with faster chips,
twice the memory per node, and twice the number of nodes in 1984. Then,
QCD was run on the last internal Caltech hypercube, the 128-node
Mark IIIfp (built by JPL), at
(measured for QCD).
This was quickly upgraded to the Mark II hypercube with faster chips,
twice the memory per node, and twice the number of nodes in 1984. Then,
QCD was run on the last internal Caltech hypercube, the 128-node
Mark IIIfp (built by JPL), at 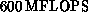 sustained [Ding:90b]. Each node of the Mark IIIfp hypercube
contains two Motorola 68020 microprocessors, one for communication and
the other for calculation, with the latter supplemented by one 68881
co-processor and a 32-bit Weitek floating point processor.
sustained [Ding:90b]. Each node of the Mark IIIfp hypercube
contains two Motorola 68020 microprocessors, one for communication and
the other for calculation, with the latter supplemented by one 68881
co-processor and a 32-bit Weitek floating point processor.
Norman Christ and Anthony Terrano built their first parallel computer
for doing lattice QCD calculations at Columbia in 1984
[Christ:84a]. It had 16 nodes, each of which was an Intel
80286/87 microprocessor, plus a TRW 22-bit floating point processor
with 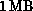 of memory, giving a total peak performance of
of memory, giving a total peak performance of 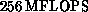 . This was improved in 1987 using Weitek rather than TRW
chips so that 64 nodes gave
. This was improved in 1987 using Weitek rather than TRW
chips so that 64 nodes gave 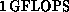 peak. In 1989, the
Columbia group finished building their third machine: a 256-node,
peak. In 1989, the
Columbia group finished building their third machine: a 256-node,
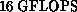 , lattice QCD computer [Christ:90a].
, lattice QCD computer [Christ:90a].
QCDPAX is the latest in the line of PAX (Parallel Array eXperiment) machines developed at the University of Tsukuba in Japan. The architecture is very similar to that of the Columbia machine. It is a MIMD machine configured as a two-dimensional periodic array of nodes, and each node includes a Motorola 68020 microprocessor and a 32-bit vector floating-point unit. Its peak performance is similar to that of the Columbia machine; however, it achieves only half the floating-point utilization for QCD code [Iwasaki:91a].
Don Weingarten initiated the GF11 project in 1984 at IBM. The GF11 is a SIMD
machine comprising 576 Weitek floating point processors, each performing at
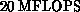 to give the total
to give the total 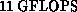 peak implied by the name.
Preliminary results for this project are given in
[Weingarten:90a;92a].
peak implied by the name.
Preliminary results for this project are given in
[Weingarten:90a;92a].
The APE (Array Processor with
Emulator) computer is basically a collection of 3081/E processors (which were
developed by CERN and SLAC for use in high energy experimental physics) with
Weitek floating-point processors attached. However, these floating-point
processors are attached in a special way-each node has four multipliers and
four adders, in order to optimize the 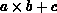 calculations, which
form the major component of all lattice QCD programs. This means that each
node has a peak performance of
calculations, which
form the major component of all lattice QCD programs. This means that each
node has a peak performance of 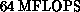 . The first small
machine-Apetto-was completed in 1986 and had four nodes yielding a peak
performance of
. The first small
machine-Apetto-was completed in 1986 and had four nodes yielding a peak
performance of 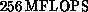 . Currently, they have a second generation
of this machine with
. Currently, they have a second generation
of this machine with 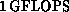 peak from 16 nodes. By 1993, the APE
collaboration hopes to have completed the
peak from 16 nodes. By 1993, the APE
collaboration hopes to have completed the 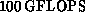 2048-node
``Apecento,'' or APE-100, based on specialized VLSI chips
that are software compatible with the original APE [Avico:89a],
[Battista:92a]. The APE-100 is a SIMD machine with the
architecture based on a three-dimensional cubic mesh of nodes.
Currently, a 128-node machine is running with a peak performance of
2048-node
``Apecento,'' or APE-100, based on specialized VLSI chips
that are software compatible with the original APE [Avico:89a],
[Battista:92a]. The APE-100 is a SIMD machine with the
architecture based on a three-dimensional cubic mesh of nodes.
Currently, a 128-node machine is running with a peak performance of
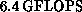 .
.
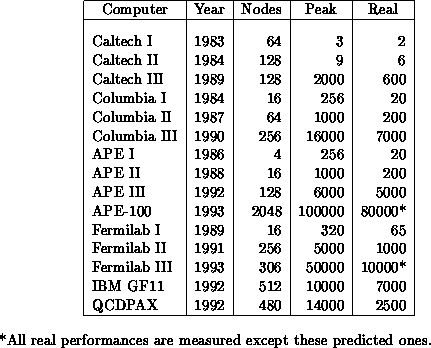
Table 4.3: Peak and Real Performances in MFLOPS of ``Homebrew'' QCD
Machines
Not to be outdone, Fermilab has also used its high energy experimental
physics emulators to construct a lattice QCD machine called ACPMAPS.
This is a MIMD machine, using a Weitek floating-point chip set on each
node. A 16-node machine, with a peak rate of 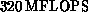 , was
finished in 1989. A 256-node machine, arranged as a
, was
finished in 1989. A 256-node machine, arranged as a 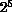 hypercube
of crates, with eight nodes communicating through a crossbar in each
crate, was completed in 1991 [Fischler:92a]. It has a peak rate
of
hypercube
of crates, with eight nodes communicating through a crossbar in each
crate, was completed in 1991 [Fischler:92a]. It has a peak rate
of 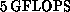 , and a sustained rate of about
, and a sustained rate of about 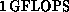 for
QCD. An upgrade of ACPMAPS is planned, with the number of nodes being
increased and the present processors being replaced with two Intel
i860 chips per node, giving a peak performance of
for
QCD. An upgrade of ACPMAPS is planned, with the number of nodes being
increased and the present processors being replaced with two Intel
i860 chips per node, giving a peak performance of 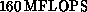 per node. These performance figures are summarized in
Table 4.3. (The ``real'' performances are the actual
performances obtained on QCD codes.)
per node. These performance figures are summarized in
Table 4.3. (The ``real'' performances are the actual
performances obtained on QCD codes.)
Major calculations have also been performed on commercial SIMD
machines, first on the ICL Distributed Array Processor (DAP) at
Edinburgh University during the period from 1982 to 1987 [Wallace:84a],
and now on the TMC Connection Machine
(CM-2); and on commercial distributed memory MIMD machines like the
nCUBE hypercube and Intel Touchstone Delta machines at Caltech.
Currently, the Connection Machine is the most powerful commercial QCD
machine available, running full QCD at a sustained rate of
approximately 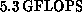 on a
on a 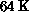 CM-2
[Baillie:89e], [Brickner:91b]. However, simulations have
recently been performed at a rate of
CM-2
[Baillie:89e], [Brickner:91b]. However, simulations have
recently been performed at a rate of 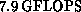 on the
experimental Intel Touchstone Delta at Caltech. This is a MIMD machine
made up of 528 Intel i860 processors connected in a two-dimensional
mesh, with a peak performance of
on the
experimental Intel Touchstone Delta at Caltech. This is a MIMD machine
made up of 528 Intel i860 processors connected in a two-dimensional
mesh, with a peak performance of 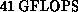 for 32-bit
arithmetic. These results compare favorably with performances on
traditional (vector) supercomputers. Highly optimized QCD code runs at
about
for 32-bit
arithmetic. These results compare favorably with performances on
traditional (vector) supercomputers. Highly optimized QCD code runs at
about 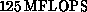 per processor on a CRAY Y-MP, or
per processor on a CRAY Y-MP, or
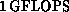 on a fully configured eight-processor machine.
on a fully configured eight-processor machine.
The generation of commercial parallel supercomputers, represented by the
CM-5 and the Intel Paragon, have a peak performance of over 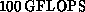 . There was a proposal for the development of a
TeraFLOPS parallel supercomputer for QCD and other numerically
intensive simulations [Christ:91a], [Aoki:91a]. The goal was
to build a
. There was a proposal for the development of a
TeraFLOPS parallel supercomputer for QCD and other numerically
intensive simulations [Christ:91a], [Aoki:91a]. The goal was
to build a 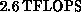 machine based on the CM-5 architecture in
collaboration with Thinking Machines Corporation, which would be ready
by 1995 at a cost of around $40 million.
machine based on the CM-5 architecture in
collaboration with Thinking Machines Corporation, which would be ready
by 1995 at a cost of around $40 million.
It is interesting to note that when the various groups began building their ``home-brew'' QCD machines, it was clear they would outperform all commercial (traditional) supercomputers; however, now that commercial parallel supercomputers have come of age [Fox:89n], the situation is not so obvious. To emphasize this, we describe QCD calculations on both the home grown Caltech hypercube and on the commercially available Connection Machine.