




When each pairwise interaction is considered, distant and nearby pairs of vortices are treated with the same care. As a result, a disproportionate amount of time is spent computing the influence of distant vortices that have little influence on the velocity of a given particle. This is not to say that the far field is to be totally ignored since the accumulation of small contributions can have a significant effect. The key element in making the velocity evaluation faster is to approximate the influence of the far field by considering groups of vortices instead of the individual vortices themselves. When the collective influence of a distant group of vortices is to be evaluated, the very accurate representation of the group provided by its vortices can be overlooked and a cruder description that retains only its most important features can be used. These would be the group location, circulation, and, possibly, some coarse approximation of its shape and vorticity distribution.
A convenient approximate representation is based on multipole expansions. It would be possible to build a fast algorithm by evaluating the multipole expansion at the location of particles that do not belong to the group. This is basically the scheme used by Barnes and Hut [Barnes:86a] (the concurrent implementation of this algorithm is discussed in Section 12.4). Greengard and Rokhlin [Greengard:87b] went a step further by proposing group-to-group interactions. In this case, the multipole expansion is transformed into a Taylor series around the center of the second group, where the influence of the first one is sought. The expansions provide an accurate representation of the velocity field when the distance between the groups is large compared to their radii.
One now needs a data structure that is going to facilitate the search for
acceptable approximations. As proposed by Appel [Appel:85a], a
binary tree is used. In that framework, a giant cluster sits on top of the
data structure; it includes all the vortex particles. It stores all the
information relevant to the group, that is, its location, its radius, and the
coefficients of the multipole expansion. In addition, it carries the address
of its two children, each of them responsible for approximately half of the
vortices of the parent group. Whenever smaller groups are sought, these
pointers are used to rapidly access the relevant information. The children
carry the description of their own group of vortices and are themselves
pointing at two smaller groups, their own children, the grandchildren of the
patriarchal group. More subgroups are created by equally dividing the
vortices of the parent groups along the ``x'' and ``y'' axis alternatively.
This splitting process stops when all groups have approximately  vortices. Then, instead of pointing toward two smaller groups, the parent
node points toward a list of vortices. This data structure provides a quick
way to access groups, from the largest to the smallest ones, and ultimately
to the individual vortices themselves. Appel's data structure is Lagrangian
since it is built on top of the vortices and moves with them. As a result,
it can be used for many time steps.
vortices. Then, instead of pointing toward two smaller groups, the parent
node points toward a list of vortices. This data structure provides a quick
way to access groups, from the largest to the smallest ones, and ultimately
to the individual vortices themselves. Appel's data structure is Lagrangian
since it is built on top of the vortices and moves with them. As a result,
it can be used for many time steps.
Comparing the speed of this algorithm with the classical 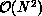 approach, the crossover occurs for as few as 150 vortices. At this point,
the extra cost of maintaining the data structure is balanced by the savings
associated with the approximate treatment of the far field. When N is
increased further, the savings outweigh the extra bookkeeping and the
proposed algorithm is faster than its competitor by a margin that increases
with the number of vortices.
approach, the crossover occurs for as few as 150 vortices. At this point,
the extra cost of maintaining the data structure is balanced by the savings
associated with the approximate treatment of the far field. When N is
increased further, the savings outweigh the extra bookkeeping and the
proposed algorithm is faster than its competitor by a margin that increases
with the number of vortices.