




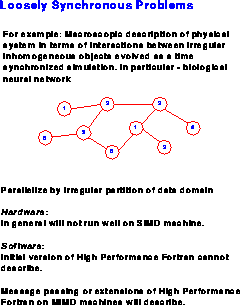
Figure 9.1: The Loosely Synchronous Problem Class
The significance of loosely synchronous
problems and their natural parallelism was an important realization
that emerged gradually (perhaps in 1987 as a clear concept) as we
accumulated results from C P research. As described in
Figure 9.1, fundamental theories often describe phenomena
in terms of a set of similar entities obeying a single law. However,
one does not usually describe practical problems in terms of their
fundamental description in a theory such as QCD in Section 4.3.
Rather, we use macroscopic concepts. Looking at society, a particle
physicist might view it as a bunch of quarks and gluons; a nuclear
physicist as a collection of protons and neutrons; a chemist as a
collection of molecules; a biochemist as a set of proteins; a
biologist as myriad cells; and a social scientist as a collection of
people. Each description is appropriate to answer certain questions,
and it is usually clear which description should be used. If we
consider a simulation of society, or a part there of, only the QCD
description is naturally synchronous. The other fields view society as
a set of macroscopic constructs, which are no longer identical and
typically have an irregular interconnect. This is caricatured in
Figure 9.1 as an irregular network. The simulation is
still data-parallel and, further, there is a critical macroscopic
synchronization-in a time-stepped simulation at every time step
P research. As described in
Figure 9.1, fundamental theories often describe phenomena
in terms of a set of similar entities obeying a single law. However,
one does not usually describe practical problems in terms of their
fundamental description in a theory such as QCD in Section 4.3.
Rather, we use macroscopic concepts. Looking at society, a particle
physicist might view it as a bunch of quarks and gluons; a nuclear
physicist as a collection of protons and neutrons; a chemist as a
collection of molecules; a biochemist as a set of proteins; a
biologist as myriad cells; and a social scientist as a collection of
people. Each description is appropriate to answer certain questions,
and it is usually clear which description should be used. If we
consider a simulation of society, or a part there of, only the QCD
description is naturally synchronous. The other fields view society as
a set of macroscopic constructs, which are no longer identical and
typically have an irregular interconnect. This is caricatured in
Figure 9.1 as an irregular network. The simulation is
still data-parallel and, further, there is a critical macroscopic
synchronization-in a time-stepped simulation at every time step
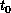 ,
, 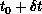 ,
, 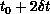 . This is an algorithmic
synchronization that ensures natural scaling parallelism, that is, that
the efficiency of Equations 3.10 and 3.11 is
given by
. This is an algorithmic
synchronization that ensures natural scaling parallelism, that is, that
the efficiency of Equations 3.10 and 3.11 is
given by
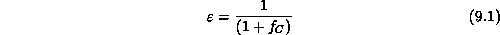
and
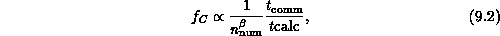
with the parameter  of Equation 3.10 equal
to zero.
of Equation 3.10 equal
to zero.  is given by Equation 3.10 in terms
of the system dimension. The efficiency only
depends on the problem grain size and not explicitly on the number of
processing nodes. As emphasized in [Gustafson:88a], these
problems scale so that if one doubles both the machine and problem
size, the speedup will also double with constant efficiency. This
situation is summarized in Figure 9.2.
is given by Equation 3.10 in terms
of the system dimension. The efficiency only
depends on the problem grain size and not explicitly on the number of
processing nodes. As emphasized in [Gustafson:88a], these
problems scale so that if one doubles both the machine and problem
size, the speedup will also double with constant efficiency. This
situation is summarized in Figure 9.2.
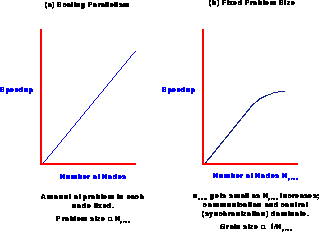
Figure 9.2: Speedup as a Function of Number of Processors 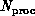
Why is there no synchronization overhead in this problem class? Picturesquely, we can say that the processors ``know'' that they are synchronized at the end of each algorithmic time step. We use time in the generalized complex system language of Section 3.3 and so it would represent, for instance, iteration number in a matrix problem. Operationally, we can describe the loosely synchronous class on a MIMD machine by the communication-calculation sequence in Figure 9.3. The update (calculate) phase can involve very different algorithms and computations for the points stored in different processors. Thus, a MIMD architecture is needed in the general case. Synchronization is provided, as in Figure 9.3 by the internode communication phases at each time step. As described in Chapters 5 and 16, this does not need, but certainly can use, the full asynchronous message-passing capability of a MIMD machine.

Figure 9.3: Communication-Calculation Phases in a Loosely Synchronous
Problem
We have split the loosely synchronous problems into two chapters, with those in Chapter 12 showing more irregularities and greater need for MIMD architectures than the applications described in this chapter. There has been no definitive study of which loosely synchronous problems can run well on SIMD machines. Some certainly can, but not all. We have discussed some of these issues in Section 6.1. If, as many expect, SIMD will remain a cost-effective architecture offered commercially, it will be important to better clarify the class of irregular problems that definitely need the full MIMD architecture.
As mentioned above, the applications in this chapter are ``modestly''
loosely synchronous. They include particle simulations
(Sections 9.2 and 9.3), solutions of partial
differential equation (Sections 9.3, 9.4,
9.5, 9.7), and circuit simulation (Sections 9.5
and 9.6). In Section 9.8, we describe an optimal
assignment algorithm that can be used for multiple target Kalman
filters and was developed for the large scale
battle management simulation of Sections 18.3 and
18.4. Section 9.9 covers the parallelization of
learning (``back-propagation'') neural nets with improved learning
methods. An interesting C P application not covered in detail in
this book was the calculation of an exchange energy in solid
P application not covered in detail in
this book was the calculation of an exchange energy in solid 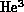 at temperatures below
at temperatures below 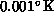 [Callahan:88a;88b].
This was our first major
use of the nCUBE-1 in production mode and Callahan suffered all the
difficulties of a pioneer with the, at the time, decidely unreliable
hardware and software. He used 250 hours on our 512-node
nCUBE-1, which was equivalent to 1000 hours of a non-vectorized CRAY X-MP implementation. In discussing
SIMD versus MIMD, one usually concentrates on the synchronization
aspects. However, Callahan's application illustrates another point;
namely, commercial SIMD machines typically have many more processors
than a comparable MIMD computer. For example, Thinking Machines
introduced the 32-node MIMD CM-5 as roughly equivalent (in price) to an
[Callahan:88a;88b].
This was our first major
use of the nCUBE-1 in production mode and Callahan suffered all the
difficulties of a pioneer with the, at the time, decidely unreliable
hardware and software. He used 250 hours on our 512-node
nCUBE-1, which was equivalent to 1000 hours of a non-vectorized CRAY X-MP implementation. In discussing
SIMD versus MIMD, one usually concentrates on the synchronization
aspects. However, Callahan's application illustrates another point;
namely, commercial SIMD machines typically have many more processors
than a comparable MIMD computer. For example, Thinking Machines
introduced the 32-node MIMD CM-5 as roughly equivalent (in price) to an
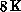 SIMD CM-2. The SIMD architecture has 256 times as many
nodes. Of course, the SIMD nodes are much simpler, but this still
implies that one needs a large enough problem to exploit this extra
number of nodes. There are some coarse-grain SIMD
machines-especially special-purpose QCD machines [Battista:92a],
[Christ:86a], [Fox:93a], [Marinari:93a]-but it is more
natural to build fine-grain machines. If the node is large, one might
as well add MIMD capability! Full matrix
algorithms, such as LU decomposition, (see Chapter 8), are often
synchronous, but do not perform very well on SIMD machines due to
insufficient parallelism [Fox:92j]. Many of the operations only
involve single rows and columns and have severe load imbalance on
fine-grain machines. Callahan's
SIMD CM-2. The SIMD architecture has 256 times as many
nodes. Of course, the SIMD nodes are much simpler, but this still
implies that one needs a large enough problem to exploit this extra
number of nodes. There are some coarse-grain SIMD
machines-especially special-purpose QCD machines [Battista:92a],
[Christ:86a], [Fox:93a], [Marinari:93a]-but it is more
natural to build fine-grain machines. If the node is large, one might
as well add MIMD capability! Full matrix
algorithms, such as LU decomposition, (see Chapter 8), are often
synchronous, but do not perform very well on SIMD machines due to
insufficient parallelism [Fox:92j]. Many of the operations only
involve single rows and columns and have severe load imbalance on
fine-grain machines. Callahan's 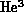 application did not exhibit
``massive'' parallelism, and so ``had'' to use a MIMD machine
irrespective of his problem's temporal structure. He used 512 nodes on the nCUBE-1 by combining three forms of
parallelism: Two came from the problem formulation with spatial and
temporal parallelism, the other from running four different parameter
values concurrently.
application did not exhibit
``massive'' parallelism, and so ``had'' to use a MIMD machine
irrespective of his problem's temporal structure. He used 512 nodes on the nCUBE-1 by combining three forms of
parallelism: Two came from the problem formulation with spatial and
temporal parallelism, the other from running four different parameter
values concurrently.
A polymer simulation [Ding:88a;88b] [Ding:88a]
[Ding:88b] by Ding and Goddard, using the reptation method,
exhibited a similar effect. There is a chain of N chemical units and
the algorithm involves special treatment of the two units at the
beginning and end of the linear polymer. The MIMD program ran
successfully on the Mark III and FPS T-Series, but the
problem is too ``small'' (parallelism of 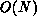 ) for this algorithm to
run on a SIMD machine even though most of the basic operations can be
run synchronously.
) for this algorithm to
run on a SIMD machine even though most of the basic operations can be
run synchronously.
This issue of available parallelism also complicates the implementation of multigrid algorithms on SIMD machines [Frederickson:88a;88b;89a;89b].