Most of the standard eigenvalue algorithms exploit projection processes in order to extract approximate eigenvectors from a given subspace. The basic idea of a projection method is to extract an approximate eigenvector from a specified low-dimensional subspace. Certain conditions are required in order to be able to extract these approximations. Once these conditions are expressed, a small matrix eigenvalue problem is obtained.
A somewhat trivial but interesting illustration of the use of projection is when the dominant eigenvalue of a matrix is computed by the power method as follows:
select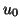
foruntil convergence do:
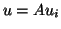
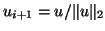
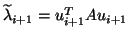
In the simplest case when the dominant eigenvalue, i.e., the
eigenvalue with largest modulus, is real and simple,
the pair
![]() converges to the eigenvector and associated (largest in modulus) eigenvalue
under mild assumptions on the initial vector.
If this eigenvalue
is complex and real arithmetic is used, then the algorithm will fail to
converge. It is possible to work in complex arithmetic by introducing
a complex initial vector, and in this way convergence will be recovered. However,
it is also possible to extract these eigenvectors by working in real
arithmetic. This is based on the observation that two successive
iterates
converges to the eigenvector and associated (largest in modulus) eigenvalue
under mild assumptions on the initial vector.
If this eigenvalue
is complex and real arithmetic is used, then the algorithm will fail to
converge. It is possible to work in complex arithmetic by introducing
a complex initial vector, and in this way convergence will be recovered. However,
it is also possible to extract these eigenvectors by working in real
arithmetic. This is based on the observation that two successive
iterates ![]() and
and ![]() will tend to belong to the
subspace spanned by the two complex conjugate eigenvectors associated
with the desired eigenvalue. Let
will tend to belong to the
subspace spanned by the two complex conjugate eigenvectors associated
with the desired eigenvalue. Let ![]() and
and ![]() be
denoted by
be
denoted by ![]() and
and ![]() , respectively. To extract the approximate
eigenvectors, we write them as linear combinations of
, respectively. To extract the approximate
eigenvectors, we write them as linear combinations of ![]() and
and
![]() :
:
The (complex) approximate pair of conjugate eigenvalues obtained from
this problem will now converge under the same conditions as those
stated for the real case. The iteration uses real vectors, yet the
process is able to extract complex eigenvalues. Clearly, the
approximate eigenvectors are complex but they need not be computed in
complex arithmetic. This is because the (real) basis ![]() is
also a suitable basis for the complex plane spanned by
is
also a suitable basis for the complex plane spanned by ![]() and
and ![]() .
.
The above idea can now be generalized from two dimensions to ![]() dimensions. Thus, a projection method consists of approximating the
exact eigenvector
dimensions. Thus, a projection method consists of approximating the
exact eigenvector ![]() , by a vector
, by a vector ![]() belonging to some subspace
belonging to some subspace
![]() referred to as the subspace of approximants
or the right subspace.
If the subspace has dimension
referred to as the subspace of approximants
or the right subspace.
If the subspace has dimension ![]() , this gives
, this gives ![]() degrees of freedom
and the next step is to impose
degrees of freedom
and the next step is to impose ![]() constraints to be able to extract
a unique solution. This is done by imposing the so-called
Petrov-Galerkin condition
that the residual vector of
constraints to be able to extract
a unique solution. This is done by imposing the so-called
Petrov-Galerkin condition
that the residual vector of ![]() be orthogonal to some subspace
be orthogonal to some subspace
![]() , referred to as the left
subspace. Though this may seem artificial, we
can distinguish between two broad classes of projection methods. In
an orthogonal projection technique the subspace
, referred to as the left
subspace. Though this may seem artificial, we
can distinguish between two broad classes of projection methods. In
an orthogonal projection technique the subspace ![]() is
the same as
is
the same as ![]() . In an
oblique projection method
. In an
oblique projection method ![]() is different from
is different from ![]() and can be completely unrelated to it.
and can be completely unrelated to it.
The construction of ![]() can be done in different ways. The above-suggested
generalization of the power method leads, if one works with all generated
vectors, to the Krylov subspace methods, that is, methods that seek the
solution in the subspace
can be done in different ways. The above-suggested
generalization of the power method leads, if one works with all generated
vectors, to the Krylov subspace methods, that is, methods that seek the
solution in the subspace