On a distributed-memory concurrent computer consisting of RISC processors, such as the IBM SP2 or the Intel MP Paragon, the performance of the Level 2 PBLAS is limited by the rate of data movement between different levels of memory within a processor. In other words, the performance of the Level 2 BLAS on each processor considerably limits the performance of the equivalent distributed operation. Table 2 shows the performance results obtained by the general matrix-vector multiply PBLAS routine PDGEMV.
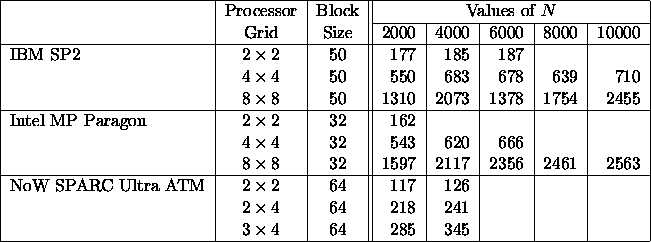
Table 2: Speed in Megaflop/s of the PBLAS Matrix-Vector
Multiply Routines
for matrices of order N with TRANS='N'
PDGEMV
This limitation
is overcome by
the Level 3
PBLAS, which
locally perform
![]() floating-point
operations on
floating-point
operations on
![]() data.
The flop rate
achieved by
every processor
for such a
distributed
operation is
then much
higher.
Table 3
shows the
performance
results obtained
by the general
matrix-matrix
multiply PBLAS
routine PDGEMM
for square matrices
of order N.
data.
The flop rate
achieved by
every processor
for such a
distributed
operation is
then much
higher.
Table 3
shows the
performance
results obtained
by the general
matrix-matrix
multiply PBLAS
routine PDGEMM
for square matrices
of order N.
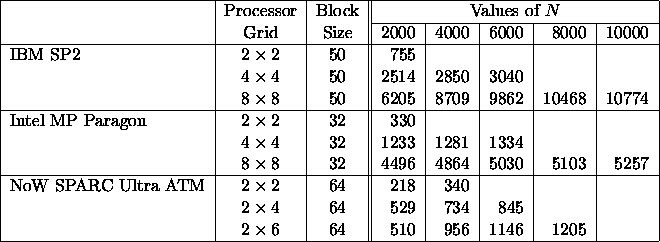
Table 3: Speed in Megaflop/s of the PBLAS Matrix-Matrix
Multiply Routines PDGEMM
for matrices of order N with TRANSA='N' and TRANSB='N'