Current Web interfaces are difficult and frustrating for the user who is attempting to locate specific information. Browsing by following hypertext links is slow and can be disorienting. Keyword searching suffers from the vocabulary mismatch problem and is unsuitable for users with imprecise information and software needs. NHSE developers are working on support for an oriented, iterative combined searching and browsing process during which a user can
The interface will be in the form of a thesaurus-based roadmap. The NHSE will define the top levels of an HPCC thesaurus, drawing on an existing HPCC glossary [4] and on the current NHSE contents to generate thesaurus terms. Subject area specialists will be called upon to refine the lower levels. The thesaurus, along with a high-level classification scheme, will form the basis of a hypertext roadmap [6]. The roadmap will include scope notes and annotations to familiarize users with various HPCC areas and will serve as a springboard for thesaurus-assisted searches. Whether the HPCC thesaurus will function as both a searching and an indexing thesaurus, or only as a searching thesaurus, depends on the size and rate of growth of the HPCC software base, as well as on the available manpower for indexing, factors which have not yet been determined.
To enable searching, cataloging information must be made available for NHSE assets. Each physical repository will be responsible for maintaining one or more network-accessible file containing such cataloging information. These files will be retrieved and indexed by an NHSE indexer on a regular basis, and the resulting searchable index will be replicated for reliability. The NHSE will use the Harvest system [1] to do the collection, indexing, and index replication, as shown in Figure 2. Harvest components include the Gatherer, the Broker, and the Replicator. The Gatherer component retrieves and summarizes files containing cataloging information. The Broker periodically collects this information from the Gatherers, using an efficient stream protocol, and constructs a searchable index. A Gatherer can access an information provider's files across the network using the FTP, gopher, or HTTP protocol, or a Gatherer can be run locally by a provider site. The Harvest Replicator module can be used to replicate the Broker's index.
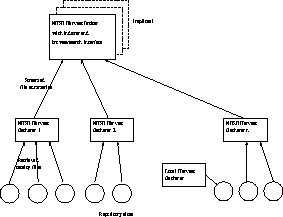
Figure 2: Indexing using Harvest