


The computational power for the Hewlett Packard systems, like the Superdome, is delivered by the PA-8800 chip. Since February this year it replaces the PA-RISC 8700+ which was as the naming suggests essentially the same as the PA-8700 just has a higher clock rate, 875 MHz instead of 750 MHz. The PA-8800 is different: it follows the trend to put two CPUs on a chip. This could be done because of the denser technology: 130 nm instead of 180 nm. This also enabled to raise the clock cycle to 1 GHz (there is also a slower 900 MHz variant). Furthermore, the bandwidth has considerably increased: from 1.6 GB/s to 6.4 GB/s per chip. Note that this is identical to the frontside bus speed of the Itanium 2 (see section Intel Itanium 2) which enables HP to exchange PA-RISC chips for Itanium 2 chips. The CPU cores on the chip are almost shrunken down versions of the former PA-8700(+). There is one difference though: the L1 instruction cache has doubled from 750 KB to 1.5 MB in two parts like the data cache was already implemented.
As there are now 2 CPUs on a chip the net bandwidth increase per CPU is a factor of 2. The larger HP systems like the Superdome is built from 4-processor cells and the chips are commonly connected to the system memory in a cell and to the cell controller that makes a cell into an SMP node and takes care of the communication with other cells, if present. The block diagram of a processor core is shown in Figure 9a.
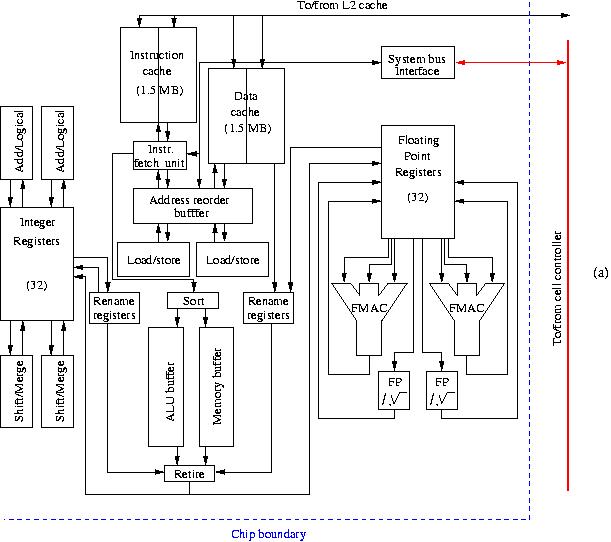
Figure 9a: Block diagram of an HP PA-RISC 8800 processor core.
The layout of the two cores and other important devices on the chip is shown in Figure 9b.
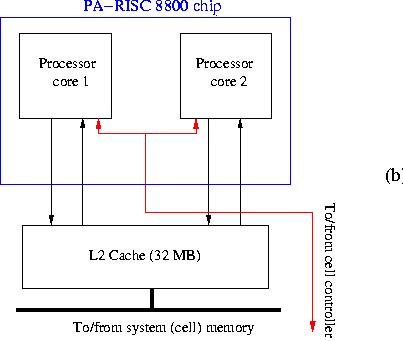
Figure 9b: Chip layout of an HP PA-RISC 8800 CPU.
A peculiarity of the PA-8x00 chips was the abcense of a secondary cache. This was compensated for by a large L1 cache is implemented: 1.5 MB instruction cache and 1.5 MB data cache. Both are 4-way set associative. The absence of the L2 cache has been amended in the PA-8800. There is now a large 32 MB L2 cache off-chip.
From the PA-8600 on the shrinking of the logic has allowed to put the L1 caches on-chip. The latency of the caches is two cycles. To ensure data to be shipped to the registers every cycle, the load/store units work "out-of-phase". So, one unit loads from one half of the data cache while the other loads from the other half. The Address Reorder Buffer sets the priority for the loads and tries to load from the alternate halves every cycle.
Like all advanced RISC processors the PA-8700(+) has out-of-order execution, the sequence of instructions being determined by the instruction reorder buffer (IRB) which contains an ALU buffer that drives the computational functional units and a memory buffer that controls the load/store units. When speculative branches have been mis-predicted the dependent instructions are retired from the IRB and new candidate instructions replace them. Branch prediction is controlled through the branch history table (BHT) but, in addition to this dynamic branch prediction, a static branch prediction can be performed at the compiler level or by execution traces of former executions of a program. The BHT was rather small in the predecessors of the PA-8600 but is now enlarged significantly to 2048 entries to get better prediction results. Also the Translation Lookaside Buffer (a component of the load/store units not shown in Figure 9a) was enlarged to 160 entries for a more effective address translation. Also there is a pre-fetch capability in the PA-8800 from the data cache.
As can be seen in Figure 9a, there are 2 floating-point units which each can deliver 2 flops per cycle but only when the operation is in the axpy form x = x + α·y. This is called a Floating Multiply Accumulate instruction (FMAC) by HP. At a clock frequency of 1 GHz this leads to a theoretical peak performance of 4 Gflop/s/CPU, so, 8 Gflop/s/chip. However, when the operations occur in another order or with another composition, 1 flop per cycle per floating-point unit can be executed with a correspondingly lower flop rate.
According to HP's roadmap at least one new generation of the PA-8x00
family is projected: the PA-8900 that will be on the market concurrently with
the IA-64 Itanium Montecito. The signals are somewhat confusing in that
respect: sometimes is also stated that the PA-RISC family will stop at this
latest PA-8800 chip (which we think to be more likely).