




The code used in this study parallelizes well for a number of reasons. The discretization is static and regular, and the same operations are applied at each grid point, even though the evolution of the system is nonlinear. Thus, the problem can be statically load balanced at the start of the code by ensuring that each processor's rectangular subdomain contains the same number of grid points. In addition, the physics, and hence the algorithm, is local so the finite difference algorithm only requires communication between nearest neighbors in the hypercube topology. The extreme regularity of the FCT technique means that it can also be efficiently used to study convective transport on SIMD concurrent computers, such as the Connection Machine, as has been done by Oran, et al. [Oran:90a].
No major changes were introduced into the sequential code in
parallelizing it for the hypercube architecture. Additional subroutines
were inserted to decompose the problem domain into rectangular
subdomains, and to perform interprocessor communication. Communication
is necessary in applying the Courant condition to determine the size of
the next time step, and in transferring field values at grid points
lying along the edge of a processor's subdomain. Single rows and
columns of field values were communicated as the algorithm required.
Some inefficiency, due to communication latency, could
have been avoided if several rows and/or columns were communicated at
the same time, but in order to avoid wasting memory on larger
communication buffers, this was not done. This choice was dictated by
the small amount of memory (about 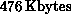 ) available on each
nCUBE-1 processor.
) available on each
nCUBE-1 processor.