




The first question that must be asked of any algorithm when a parallel version is being considered is, ``What does it do?'' Surprisingly, this question is often quite hard to answer. Vague responses such as ``some sort of linear algebra'' are quite common and even if the name of the algorithm is actually known, it is quite surprising how often codes are ported without anyone actually having a good impression of what the code does.
One attempt to shed light on these issues by providing a data visualization service is vtool. One takes the original (sequential) source code and runs it through a preprocessor that instruments various types of data access. The program is then compiled with a special run time library and run in the normal manner. The result is a database describing the ways in which the algorithm or application makes use of its data.
Once this has been collected, vtool provides a service analogous to a home VCR which allows the application to be ``played back'' to show the memory accesses being made. Sample output is shown in Figure 5.9.
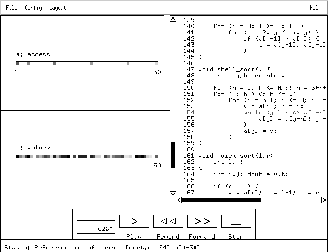
Figure 5.9: Analysis of a Sorting Algorithm Using vtool
The basic idea is to show ``pictures'' of arrays together with a ``hot spot'' that shows where accesses and updates are being made. As the hot spot moves, it leaves behind a trail of continuingly fading colors that dramatically show the evolution of the algorithm. As this proceeds, the corresponding source code can be shown and the whole simulation can be stopped at any time so that a particularly interesting sequence can be replayed in slow motion or even one step at a time, both forward and backward.
In addition to showing simple access patterns, the display can also show the values being stored into arrays, providing a powerful way of debugging applications.
In the parallel processing arena, this tool is normally used to understand how an algorithm works at the level of its memory references. Since most parallel programs are based on the ideas of data distribution, it is important to know how the values at a particular grid point or location in space depend on those of neighbors. This is fundamental to the selection of a parallelization method. It is also central to the understanding of how the parallel and sequential versions of the code will differ which becomes important when the optimization process begins.
It should be mentioned in passing that we have been surprised in using this tool how often people's conceptions of the way that numerical algorithms work are either slightly or completely revised after seeing the visualization system at work.