




Our plan was to use MOOS II to study dynamic load balancing (Chapter 11), and eventually incorporate a dynamic load balancer in the MOOSE system. However, our first implementation of a dynamic load balancer, along the lines of [Fox:86h], convinced us that dynamic load balancing is a difficult and many-faceted issue, so the net result was a better understanding of the subject's complexities rather than a general-purpose balancer.
The prototype dynamic load balancer worked as shown in Figure 15.5 and is appropriate for applications where the number of MOOSE teams in an application is constant. However, the amount of work performed by individual teams changes slowly with time. A centralized load manager on node 0 keeps statistics on all the teams in the machine. At regular intervals, the teams report the amount of computation and communication they have done since the last report, and the central manager computes the new load balance. If the balance can be improved significantly, some teams are relocated to new nodes, and the cycle continues.
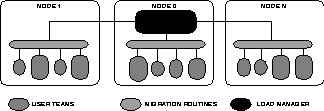
Figure 15.5: One Simple Load-Balancing Scheme Implemented in MOOS II
This centralized approach is simple and successful in that it relocates as few teams as possible to maintain the balance; its drawback is that computing which teams to move becomes a sequential bottleneck. For instance, for 256 teams on 16 processors, a simulated annealing optimization takes about 1.2 seconds on the iPSC/1, while the actual relocation process only takes about 0.3 seconds, so the method is limited to applications where load redistribution needs only to be done every 10 seconds or so. The lesson here is that, to be viable, the load optimization step itself must be parallelized. The same conclusion will also hold for any other distributed-memory machine, since the ratio of computation time to optimization time is fairly machine-independent.