




The ultimate goal of the programmer is peak performance on the target computer. The realization of peak performance requires the understanding of many subtle relationships between the algorithm, the program, and the target machine architecture. Factors such as input data size, data dependences in the code, target machine characteristics, and the data partitioning scheme are related in very nonintuitive ways, and jointly determine the performance of the program. Thus, a data partitioning scheme that is chosen purely on the basis of some algorithmic property, may not always be the best choice.
Let us examine the relationship between these aspects more closely, to illustrate the subtle complexities that are involved in choosing the partitioning of the data domain. Consider the following program:\
double precision A(N, N), B(N, N)
*
do k=1, cycles
do j=1,N
do i=2,N-1
A(i, j) =
enddo
enddo
do j=2,N-1
do i=2,N-1
B(i,j) =
A(i, j-1), A(i, j+1) )
enddo
enddo
enddo
end
MMMMMMMMMMMMMMMMMMMMMMMMMM¯example (A, B, N)
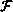 ( B(i-1, j), B(i+1, j) )
( B(i-1, j), B(i+1, j) )
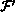 ( A(i-1, j), A(i+1, j), A(i, j),
( A(i-1, j), A(i+1, j), A(i, j),
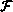 and
and 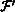 represent functions with 4 and 10 double-precision
floating-point operations, respectively. This program segment does not
represent any particular realistic computation; rather, it was
chosen to illustrate all the aspects of our argument using a small
piece of code. The program segment was executed on 64 processors of an
nCUBE, with array sizes ranging from N = 64 to N =
320. A and B were first partitioned as columns, so that each
processor was assigned
represent functions with 4 and 10 double-precision
floating-point operations, respectively. This program segment does not
represent any particular realistic computation; rather, it was
chosen to illustrate all the aspects of our argument using a small
piece of code. The program segment was executed on 64 processors of an
nCUBE, with array sizes ranging from N = 64 to N =
320. A and B were first partitioned as columns, so that each
processor was assigned 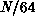 successive columns. The program was then
run once again, this time with A and B partitioned as blocks, so that
each processor was assigned a block of
successive columns. The program was then
run once again, this time with A and B partitioned as blocks, so that
each processor was assigned a block of 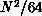 elements. The
resulting execution and communication times for column and block
partitioning schemes are shown in Figure 13.6. The
communication time was measured by removing all computation in the
loops.
elements. The
resulting execution and communication times for column and block
partitioning schemes are shown in Figure 13.6. The
communication time was measured by removing all computation in the
loops.
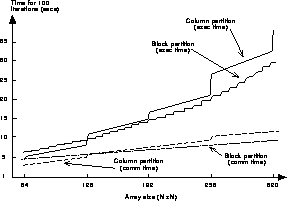
Figure 13.6: Timing results on an nCUBE, using 64 processors.
When employing a column partitioning scheme for arrays A and B, communication
is only necessary after the first j loop. Each processor has to
exchange boundary values with its left and right neighbor. In a block
partitioning scheme, each processor has to communicate with its four neighbors
after the first loop and with its north and south neighbors after the second
loop. For small message lengths, the communication cost is dominated
by the message startup time, whereas the transmission cost begins to dominate
as the messages get longer (i.e., more data is exchanged at each
communication step). This explains why communication cost for the column
partition is greater than for the block partition for array sizes larger than
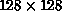 . It is clear from the graph that column partitioning is
preferable when the array sizes are less than
. It is clear from the graph that column partitioning is
preferable when the array sizes are less than 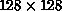 , and block
partitioning is preferable for larger sizes.
, and block
partitioning is preferable for larger sizes.
The steps in the execution time graphs are caused mainly by load imbalance
effects. For example, the step between N = 128 and N = 129 for the column
partition is due to the fact that for size 129 one subdomain has an
extra column, so that the processor assigned to that subdomain is still busy
after all the others have finished, causing load imbalance in the system.
Similar behavior can be observed for the block partition, but here the steps
occur at smaller increments of the array size N. The steps in the
communication time graphs are due to the fact that the packet size on the
nCUBE is 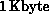 , so that messages that are even a few bytes
longer need an extra packet to be transmitted.
, so that messages that are even a few bytes
longer need an extra packet to be transmitted.
The above example indicates that several factors contribute to the observed performance of a chosen partitioning scheme, making it difficult for a human to predict this behavior statically. Our aim is to make the programmer aware of these performance effects without having to run the program on the target computer. We hope to do this by providing an interactive tool, that can give performance estimates in response to a data layout specification. The tool's performance estimates will allow the programmer to gauge the effect of a data partitioning scheme and thus provide some guidance in making a better choice.