




In the GCPIC electrostatic code, the partitioning of the grid was static. The grid was partitioned so that the computational load of the processors was initially balanced. As simulations progress and particles move among processors, the spatial distribution of the particles can change, leading to load imbalance. This can severely degrade the parallel efficiency of the push stage of the computation. To avoid this, dynamic load balancing has been implemented in a one-dimensional electromagnetic code [Liewer:90a] and a two-dimensional electrostatic code [Ferraro:93a].
To implement dynamic load balancing, the grid is
repartitioned into new subdomains with roughly equal numbers of
particles as the simulation progresses. The repartitioning is not done
at every time step. The load imbalance is monitored at a
user-specified interval. When the imbalance becomes sufficiently
large, the grid is repartitioned and the particles moved to the
appropriate processors, as necessary. The load was judged sufficiently
imbalanced to warrant load balancing when the number of particles per
processor deviated from the ideal value 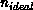 (= number of
particles/number of processors) by
(= number of
particles/number of processors) by 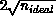 , for example,
twice the statistical fluctuation level.
, for example,
twice the statistical fluctuation level.
The dynamic load balancing is performed during the push stage of the computation. Specifically, the new grid partitions are computed after the particle positions have been updated, but before the particles are moved to new processors to avoid an unnecessary moving of particles. If the loads are sufficiently balanced, the subroutine computing the new grid partitions is not called. The subroutine, which moves the particles to appropriate processors, is called in either case.
To accurately represent the physics, a particle cannot move more than one grid cell per time step. As a result, in the static one-dimensional code, the routine which moves particles to new processors only had to move particles to nearest-neighbor processors. To implement dynamic load balancing, this subroutine had to be modified to allow particles to be moved to processors any number of steps away. Moving the particles to new processors after grid repartitioning can add significant overhead; however, this is incurred only at time steps when load balancing occurs.
The new grid partitions are computed by a very simple method which adds
very little overhead to the parallel code. Each processor constructs
an approximation to the plasma density profile, 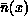 , and uses
this to compute the grid partitioning to load balance. To construct the approximate density profile, each processor
sends the locations of its current subdomain boundaries and its current
number of particles to all other processors. From this information,
each processor can compute the average plasma density in each processor
and from this can create the approximate-to-density profile (with as
many points as processors). This approximate profile is used to
compute the grid partitioning which approximately divides the particles
equally among the processors. This is done by determining the set of
subdomain boundaries
, and uses
this to compute the grid partitioning to load balance. To construct the approximate density profile, each processor
sends the locations of its current subdomain boundaries and its current
number of particles to all other processors. From this information,
each processor can compute the average plasma density in each processor
and from this can create the approximate-to-density profile (with as
many points as processors). This approximate profile is used to
compute the grid partitioning which approximately divides the particles
equally among the processors. This is done by determining the set of
subdomain boundaries 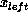 and
and 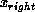 such that
such that
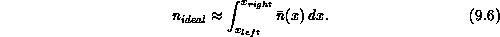
Linear interpolation of the approximate profile is used in the numerical
integration. The actual plasma density profile could also be used in the
integration to determine the partitions. No additional computation would be
necessary to obtain the local (within a processor) 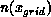 because it
is already computed for the field solution stage. However, it would
require more communication to make the density profile global. Other
methods of calculating new subdomain boundaries, such as sorting
particles, require a much larger amount of communication and
computational overhead.
because it
is already computed for the field solution stage. However, it would
require more communication to make the density profile global. Other
methods of calculating new subdomain boundaries, such as sorting
particles, require a much larger amount of communication and
computational overhead.