




By the late 1980s, truly powerful parallel systems began to appear. The Meiko system at Edinburgh University, is an example; by 1989, that computer had 400 T800s [Wallace:88a]. The system was being used for a number of traditional scientific computations in physics, chemistry, engineering, and other areas [Wexler:89a]. The system software for transputer-based systems had evolved to resemble the message-passing system software available on hypercubes. Although the transputer's two-dimensional mesh connection is in principle less efficient than hypercube connections, for systems of moderate size (only a few hundred processors), the difference is not significant for most applications. Further, any parallel architecture deficiencies were counterbalanced by the transputer's excellent communication channel performance.
Three new SIMD fine-grain systems were introduced in the
late 1980s: the CM-2, the MasPar, and a new version of
the DAP. The CM-2 is a version of the original Connection
Machine [Hillis:85a;87a]
that has been enhanced with
Weitek floating-point units, one for each 32 single-bit processors, and
optional large memory. In its largest configuration, such as is
installed at Los Alamos National Laboratory, there are 64K single-bit
processors, 2048 64-bit floating-point processors, and 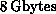 of memory. The CM-2 has been measured at
of memory. The CM-2 has been measured at 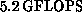 running the
unlimited Linpack benchmark solving a linear system of order 26,624 and
even higher performance on some applications, e.g.,
seismic data processing [Myczkowski:91a] and QCD
[Brickner:91b], [Liu:91a]. It has attracted widespread
attention both because of its extremely high performance and its
relative ease of use [Boghosian:90a], [Hillis:86a;87b].
For problems that are
naturally data parallel, the CM Fortran language and compiler provide a
relatively easy way to implement programs and get high performance.
running the
unlimited Linpack benchmark solving a linear system of order 26,624 and
even higher performance on some applications, e.g.,
seismic data processing [Myczkowski:91a] and QCD
[Brickner:91b], [Liu:91a]. It has attracted widespread
attention both because of its extremely high performance and its
relative ease of use [Boghosian:90a], [Hillis:86a;87b].
For problems that are
naturally data parallel, the CM Fortran language and compiler provide a
relatively easy way to implement programs and get high performance.
The MasPar and the DAP are smaller systems that are aimed more at
excellent price performance than at supercomputer levels of
performance. The new DAP is front-ended by Sun workstations or VAXes.
This makes it much more affordable and compatible with modern computing
environments than when it required an ICL front end. DAPs have been
built in ruggedized versions that can be put into vehicles, flown in
airplanes, and used on ships, and have found many uses in signal
processing and military applications. They are also used for general
scientific work. The MasPar is the newest SIMD system. Its
architecture constitutes an evolutionary approach of fine-grain SIMD
combined with enhanced floating-point performance coming from the use
of 4-bit (Maspar MP-1) or 32-bit (Maspar MP-2) basic SIMD units.
Standard 64-bit floating-point algorithms implemented on a (SIMD)
machine built around an l bit CPU take time of order 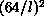 machine instructions. The DAP and CM-1,2 used l=1 and here the CM-2
and later DAP models achieve floating-point performance with special
extra hardware rather than by increasing l.
machine instructions. The DAP and CM-1,2 used l=1 and here the CM-2
and later DAP models achieve floating-point performance with special
extra hardware rather than by increasing l.
Two hypercubes became available just as the decade ended: the second
generation nCUBE, popularly known as the nCUBE-2, and the
Intel iPSC/860. The nCUBE-2 can be configured with up to 8K nodes;
that configuration would have a peak speed of 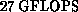 . Each
processor is still on a single chip along with all the communications
channels, but it is about eight times faster than its predecessor-a
little over
. Each
processor is still on a single chip along with all the communications
channels, but it is about eight times faster than its predecessor-a
little over 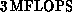 . Communication bandwidth
is also a factor of eight higher. The result is a potentially very
powerful system. The nCUBE-2 has a custom microprocessor that is
instruction-compatible with the first-generation system. The largest
system known to have been built to date is a 1024 system installed at
Sandia National Laboratories. The unlimited size Linpack benchmark for
this system yielded a performance of
. Communication bandwidth
is also a factor of eight higher. The result is a potentially very
powerful system. The nCUBE-2 has a custom microprocessor that is
instruction-compatible with the first-generation system. The largest
system known to have been built to date is a 1024 system installed at
Sandia National Laboratories. The unlimited size Linpack benchmark for
this system yielded a performance of 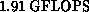 solving a linear
system of order 21,376.
solving a linear
system of order 21,376.
The second hypercube introduced in 1989 (and first shipped to a customer,
Oak Ridge, in January 1990), the Intel iPSC/860, has a
peak speed of over 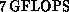 . While the communication speed
between nodes is very low compared to the speed of the i860 processor,
high speeds can be achieved for problems that do not require extensive
communication or when the data movement is planned carefully. For
example, the unlimited size Linpack benchmark on the largest
configuration iPSC/860, 128 processors, ran at
. While the communication speed
between nodes is very low compared to the speed of the i860 processor,
high speeds can be achieved for problems that do not require extensive
communication or when the data movement is planned carefully. For
example, the unlimited size Linpack benchmark on the largest
configuration iPSC/860, 128 processors, ran at 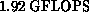 when
solving a system of order 8,600.
when
solving a system of order 8,600.
The iPSC/860 uses the Intel i860 microprocessor, which has a peak speed
of 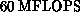 full precision and
full precision and 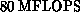 with 32-bit precision.
In mid-1991, a follow-on to Intel iPSC/860, the Intel Touchstone
Delta System, reached a Linpack speed of
with 32-bit precision.
In mid-1991, a follow-on to Intel iPSC/860, the Intel Touchstone
Delta System, reached a Linpack speed of 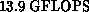 for a system of order 25,000. This was done on 512 i860 nodes of the
Delta System. This machine has a peak speed of
for a system of order 25,000. This was done on 512 i860 nodes of the
Delta System. This machine has a peak speed of 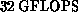 and
and
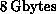 of memory and is a one-of-a-kind system built for a
consortium of institutions and installed at California Institute of
Technology. Although the C
of memory and is a one-of-a-kind system built for a
consortium of institutions and installed at California Institute of
Technology. Although the C P project is finished at Caltech, many
C
P project is finished at Caltech, many
C P applications have very successfully used the Delta. The Delta
uses a two-dimensional mesh connection scheme with mesh routing chips
instead of a hypercube connection scheme. The Intel
Paragon, a commercial product that is the successor to
the iPSC/860 and the Touchstone Delta, became available in the fall of
1992. The Paragon has the same connection scheme as the Delta. Its
maximum configuration is 4096 nodes. It uses a second generation
version of the i860 microprocessor and has a peak speed of
P applications have very successfully used the Delta. The Delta
uses a two-dimensional mesh connection scheme with mesh routing chips
instead of a hypercube connection scheme. The Intel
Paragon, a commercial product that is the successor to
the iPSC/860 and the Touchstone Delta, became available in the fall of
1992. The Paragon has the same connection scheme as the Delta. Its
maximum configuration is 4096 nodes. It uses a second generation
version of the i860 microprocessor and has a peak speed of 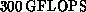 .
.
The BBN TC2000 is another important system introduced in the late 1980s. It provides a shared-memory programming environment supported by hardware. It uses a multistage switch based on crossbars that connect processor memory pairs to each other [Karplus:87a, pp. 137-146], [BBN:87a]. The BBN TC2000 uses Motorola 88000 Series processors. The ratio of speeds between access to data in cache, to data respectively in the memory local to a processor, and to data in some other processor's memory, is approximately one, three and seven. Therefore, there is a noticeable but not prohibitive penalty for using another processor's memory. The architecture is scalable to over 500 processors, although none was built of that size. Each processor can have a substantial amount of memory, and the operating system environment is considered attractive. This system is one of the few commercial shared-memory MIMD computers that can scale to large numbers of nodes. It is no longer in production; the BBN Corporation terminated its parallel computer activities in 1991.