




During this period, many new systems were launched by commercial companies, and several were quite successful in terms of sales. The two most successful were the Sequent and the Encore [Karplus:87a, pp. 111-126] products. Both were shared-memory, bus-connected multiprocessors of moderate parallelism. The maximum number of processors on the Encore product was 20; on the Sequent machine initially 16 and later 30. Both provided an extremely stable UNIX environment and were excellent for time-sharing. As such, they could be considered VAX killers since VAXes were the time-sharing system of choice in research groups in those days. The Sequent and the Encore provided perhaps a cost performance better by a factor of 10, as well as considerably higher total performance than could be obtained on a VAX at that time. These systems were particularly useful for smaller jobs, for time-sharing, and for learning to do parallel computing. Perhaps their most impressive aspect was the reliability of both hardware and software. They operated without interruption for months at a time, just as conventional mini-supercomputers did. Their UNIX operating system software was familiar to many users and, as mentioned before, very stable. Unlike most parallel computers whose system software requires years to mature, these systems had very stable and responsive system software from the beginning.
Another important system during this period was the Alliant [Karplus:87a, pp. 35-44]. The initial model featured up to eight vector processors, each of moderate performance. But when used simultaneously, they provided performance equivalent to a sizable fraction of a CRAY processor. A unique feature at the time was a Fortran compiler that was quite good at automatic vectorization and also reasonably good at parallelization. These compiler features, coupled with its shared memory, made this system relatively easy to use and to achieve reasonably good performance. The Alliant also supported the C language, although initially there was no vectorization or parallelization available in C. The operating system was UNIX-based. Because of its reasonably high floating-point performance and ease of use, the Alliant was one of the first parallel computers that was used for real applications. The Alliant was purchased by groups who wanted to do medium-sized computations and even computations they would normally do on CRAYs. This system was also used as a building block of the Cedar architecture project led by D. Kuck [Kuck:86a].
Advances in compiling technology made wide-instruction word machines an interesting and, for a few years, commercially viable architecture. The Multiflow and Cydrome systems both had compilers that effectively exploited very fine-grain parallelism and scheduling of floating-point pipelines within the processing units. Both these systems attempted to get parallelism at the instruction level from Fortran programs-the so-called dusty decks that might have convoluted logic and thus be very difficult to vectorize or parallelize in a large-grain sense. The price performance of these systems was their main attraction. On the other hand, because these systems did not scale to very high levels of performance, they were relegated to the super-minicomputer arena. An important contribution they made was to show dramatically how far compiler technology had come in certain areas.
As was mentioned earlier, hypercubes were produced by Intel,
nCUBE, Ametek, and Floating Point Systems Corporation in
the mid-1980s. Of these, the most significant product was the nCUBE with its high degree of integration and a configuration of up
to 1024 nodes [Palmer:86a], [nCUBE:87a]. It was pivotal in
demonstrating that massively parallel MIMD medium-grain computers are
practical. The nCUBE featured a complete processor on a single chip,
including all channels for connecting to the other nodes so that one
chip plus six memory chips constituted an entire node. They were
packaged on boards with 64 nodes so that the system was extremely
compact, air-cooled, and reliable. Caltech had an early 512-node
system, which was used in many C P calculations, and soon afterwards
Sandia National Laboratories installed the 1024-node system. A great
deal of scientific work was done on those two machines and they are
still in use. The 1024-node Sandia machine got the world's attention
by demonstrating speedups of 1000 for several applications
[Gustafson:88a]. This was particularly significant because it was
done during a period of active debate as to whether MIMD systems could
provide speedups of more than a hundred. Amdahl's law [Amdahl:67a] was cited as a reason why it would not be
possible to get speedups greater than perhaps a hundred, even if one
used 1000 processors.
P calculations, and soon afterwards
Sandia National Laboratories installed the 1024-node system. A great
deal of scientific work was done on those two machines and they are
still in use. The 1024-node Sandia machine got the world's attention
by demonstrating speedups of 1000 for several applications
[Gustafson:88a]. This was particularly significant because it was
done during a period of active debate as to whether MIMD systems could
provide speedups of more than a hundred. Amdahl's law [Amdahl:67a] was cited as a reason why it would not be
possible to get speedups greater than perhaps a hundred, even if one
used 1000 processors.
Towards the end of the mid-1980s, transputer-based systems
[Barron:83a], [Hey:88a], both large and small, began to
proliferate, especially in Europe but also in the United States. The
T800 transputer was like the nCUBE processor, a single-chip system with
built-in communications channels, and it had respectable floating point
performance-a peak speed of nearly 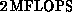 and frequently
achieved speeds of 1/2 to
and frequently
achieved speeds of 1/2 to 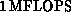 . They provided a convenient
building block for parallel systems and were quite cost-effective.
Their prevalent use at the time was in boards with four or eight
transputers that were attached to IBM PCs, VAXes, or other workstations.
. They provided a convenient
building block for parallel systems and were quite cost-effective.
Their prevalent use at the time was in boards with four or eight
transputers that were attached to IBM PCs, VAXes, or other workstations.