The performance of Level 2 PBLAS routines is dependent on the performance of Level 2 BLAS routines which is dependent on the bulk transfer rate from main memory.
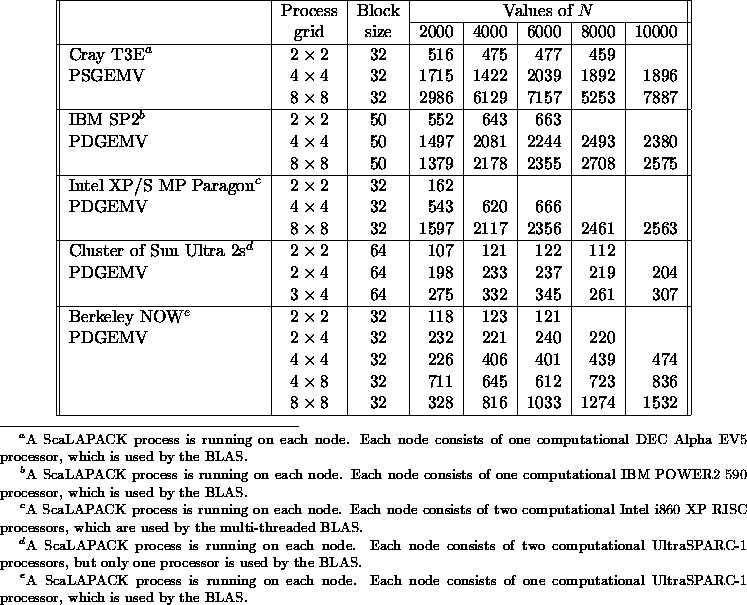
Table 5.6: Speed in Mflop/s for the PBLAS matrix-vector
multiply routine PSGEMV/PDGEMV
Table 5.6
shows execution rates for the 64-bit matrix-vector
multiply PBLAS routine PSGEMV /PDGEMV .
The rates listed are for a matrix-vector
product ![]() , where A
is a square matrix of order N and x and
y are vectors that are both distributed
over a process column.
, where A
is a square matrix of order N and x and
y are vectors that are both distributed
over a process column.
The Level 3 PBLAS are not necessarily limited by memory bandwidth because they perform many flops for each word involved. The flop rate is correspondingly higher. Table 5.7
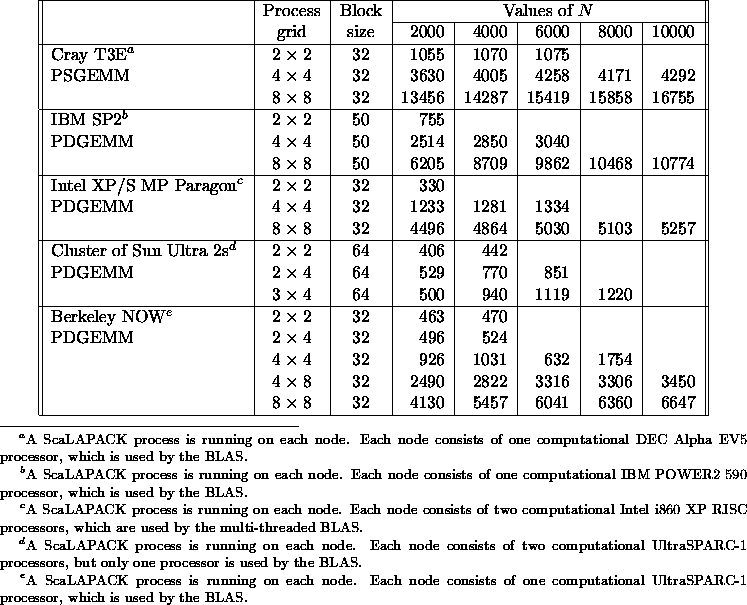
Table 5.7: Speed in Mflop/s for the PBLAS matrix-matrix
multiply routine PSGEMM/PDGEMM
shows the performance
results obtained by
the general matrix-matrix
multiply PBLAS routine
PSGEMM /PDGEMM . These
results have been
obtained for the
matrix-matrix
multiply operation
![]() ,
where A, B, and C
are square matrices
of order N.
,
where A, B, and C
are square matrices
of order N.