Libpvm provides functions to pack all of the primitive data types into a message, in one of several encoding formats. There are five sets of encoders and decoders. Each message buffer has a set associated with it. When creating a new message, the encoder set is determined by the format parameter to pvm_mkbuf(). When receiving a message, the decoders are determined by the encoding field of the message header. The two most commonly used ones pack data in raw (host native) and default (XDR) formats. Inplace encoders pack descriptors of the data (the frags point to static data), so the message is sent without copying the data to a buffer. There are no inplace decoders. Foo encoders use a machine-independent format that is simpler than XDR; these encoders are used when communicating with the pvmd. Alien decoders are installed when a received message can't be unpacked because its encoding doesn't match the data format of the host. A message in an alien data format can be held or forwarded, but any attempt to read data from it results in an error.
Figure ![]() shows libpvm message management.
To allow the PVM programmer to handle
message buffers,
they are labeled with integer message id's (MIDs) ,
which are simply indices into the message heap.
When a message buffer is freed,
its MID is recycled.
The heap
starts out small and
is extended if it becomes full.
Generally,
only a few messages exist at any time,
unless an application explicitly stores them.
shows libpvm message management.
To allow the PVM programmer to handle
message buffers,
they are labeled with integer message id's (MIDs) ,
which are simply indices into the message heap.
When a message buffer is freed,
its MID is recycled.
The heap
starts out small and
is extended if it becomes full.
Generally,
only a few messages exist at any time,
unless an application explicitly stores them.
A vector of functions for encoding/decoding primitive types (struct encvec) is initialized when a message buffer is created. To pack a long integer, the generic pack function pvm_pklong() calls (message_heap[mid].ub_codef->enc_long)() of the buffer. Encoder vectors were used for speed (as opposed to having a case switch in each pack function). One drawback is that every encoder for every format is touched (by naming it in the code), so the linker must include all the functions in every executable, even when they're not used.
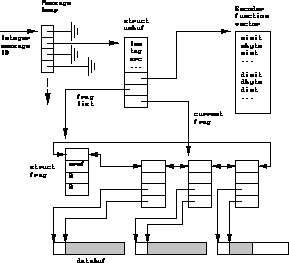
Figure: Message storage in libpvm