PVM uses a task identifier (TID) to address pvmds,
tasks, and groups of tasks within a virtual machine.
The TID contains four fields, as shown in Figure ![]() .
Since the TID is used so heavily,
it is made to fit into the largest integer data type (32 bits) available
on a wide range of machines.
.
Since the TID is used so heavily,
it is made to fit into the largest integer data type (32 bits) available
on a wide range of machines.
The fields S, G, and H have global meaning: each
pvmd of a virtual machine interprets them in the same way.
The H field contains a host number relative to the virtual machine.
As it starts up,
each pvmd is configured with a unique host number
and therefore ``owns''
part of the TID address space.
The maximum number of hosts in a virtual machine is limited to
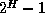 (4095).
The mapping between host numbers and hosts is known to each pvmd,
synchronized by a global host table.
Host number zero is used,
depending on context,
to refer to the local pvmd
or a shadow pvmd, called pvmd' (Section
(4095).
The mapping between host numbers and hosts is known to each pvmd,
synchronized by a global host table.
Host number zero is used,
depending on context,
to refer to the local pvmd
or a shadow pvmd, called pvmd' (Section ![]() ).
).
The S bit is used to address pvmds, with the H field set to the host number and the L field cleared. This bit is a historical leftover and causes slightly schizoid naming; sometimes pvmds are addressed with the S bit cleared. It should someday be reclaimed to make the H or L space larger.
Each pvmd is allowed to assign private meaning to the L field
(with the H field set to its own host number),
except that ``all bits cleared''
is reserved to mean the pvmd itself.
The L field is 18 bits wide,
so up to 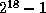 tasks can exist concurrently on each host.
In the generic Unix port,
L values are assigned by a counter,
and
the pvmd maintains a map between L values and Unix process id's.
Use of the L field in multiprocessor ports is described in Section
tasks can exist concurrently on each host.
In the generic Unix port,
L values are assigned by a counter,
and
the pvmd maintains a map between L values and Unix process id's.
Use of the L field in multiprocessor ports is described in Section ![]() .
.
The G bit is set to form multicast addresses (GIDs),
which refer to groups of tasks.
Multicasting is described in Section ![]() .
.
The design of the TID enables the implementation to meet the design goals. Tasks can be assigned TIDs by their local pvmds without off-host communication. Messages can be routed from anywhere in a virtual machine to anywhere else, by hierarchical naming. Portability is enhanced because the L field can be redefined. Finally, space is reserved for error codes. When a function can return a vector of TIDs mixed with error codes, it is useful if the error codes don't correspond to legal TIDs. The TID space is divided up as follows:

Naturally, TIDs are intended to be opaque to the application, and the programmer should not attempt to predict their values or modify them without using functions supplied in the programming library. More symbolic naming can be obtained by using a name server library layered on top of the raw PVM calls, if the convenience is deemed worth the cost of name lookup.
