Parallelism in distributed-memory environments such as PVM may also be
achieved by partitioning the overall workload in terms of different
operations. The most obvious example of this form of decomposition
is with respect to the three stages of typical program execution,
namely, input, processing, and result output. In function decomposition,
such an application may consist of three separate and distinct
programs, each one dedicated to one of the three phases.
Parallelism is obtained by concurrently executing the three programs
and by establishing a "pipeline" (continuous or quantized) between
them. Note, however, that in such a scenario, data parallelism may
also exist within each phase. An example is shown in Figure ![]() ,
where distinct functions are realized as PVM components, with multiple
instances within each component implementing portions of different
data partitioned algorithms.
,
where distinct functions are realized as PVM components, with multiple
instances within each component implementing portions of different
data partitioned algorithms.
Although the concept of function decomposition is illustrated by
the trivial example above, the term is generally used to signify
partitioning and workload allocation by function within
the computational phase. Typically, application computations
contain several different subalgorithms-sometimes on the
same data (the MPSD or multiple-program single-data scenario),
sometimes in a pipelined sequence of transformations, and sometimes
exhibiting an unstructured pattern of exchanges. We illustrate
the general functional decomposition paradigm by considering the
hypothetical simulation of an aircraft consisting of multiple
interrelated and interacting, functionally decomposed subalgorithms.
A diagram providing an overview of this example is shown in
Figure ![]() (and will also be used in a later chapter dealing
with graphical PVM programming).
(and will also be used in a later chapter dealing
with graphical PVM programming).
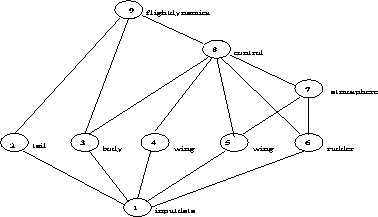
Figure: Function decomposition example
In the figure, each node or circle in the "graph" represents a functionally decomposed piece of the application. The input function distributes the particular problem parameters to the different functions 2 through 6, after spawning processes corresponding to distinct programs implementing each of the application subalgorithms. The same data may be sent to multiple functions (e.g., as in the case of the two wing functions), or data appropriate for the given function alone may be delivered. After performing some amount of computations these functions deliver intermediate or final results to functions 7, 8, and 9 that may have been spawned at the beginning of the computation or as results become available. The diagram indicates the primary concept of decomposing applications by function, as well as control and data dependency relationships. Parallelism is achieved in two respects-by the concurrent and independent execution of modules as in functions 2 through 6, and by the simultaneous, pipelined, execution of modules in a dependency chain, as, for example, in functions 1, 6, 8, and 9 .