Crowd computations typically involve three phases. The first is the initialization of the process group; in the case of node-only computations, dissemination of group information and problem parameters, as well as workload allocation, is typically done within this phase. The second phase is computation. The third phase is collection results and display of output; during this phase, the process group is disbanded or terminated.
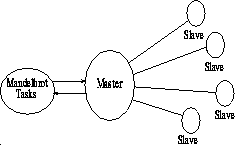
The master-slave model is illustrated below, using the well-known
Mandelbrot
set computation which is representative of the class of
problems termed ``embarrassingly''
parallel . The computation
itself involves applying a recursive function to a collection of
points in the complex plane until the function values either
reach a specific value or begin to diverge. Depending upon
this condition, a graphical representation of each point in the plane
is constructed. Essentially, since the function outcome depends
only on the starting value of the point (and is independent of
other points), the problem
can be partitioned into
completely independent portions, the algorithm applied to each, and
partial results combined using simple combination schemes. However,
this model permits dynamic load balancing,
thereby allowing the processing elements to
share the workload unevenly. In this and subsequent examples within
this chapter, we only show a skeletal form of the algorithms, and
also take syntactic liberties with the PVM routines in the interest
of clarity. The control structure of the master-slave class of
applications is shown in Figure ![]() .
.
{Master Mandelbrot algorithm.}
{Initial placement}
for i := 0 to NumWorkers - 1
pvm_spawn(<worker name>) {Start up worker i}
pvm_send(<worker tid>,999) {Send task to worker i}
endfor
{Receive-send}
while (WorkToDo)
pvm_recv(888) {Receive result}
pvm_send(<available worker tid>,999)
{Send next task to available worker}
display result
endwhile
{Gather remaining results.}
for i := 0 to NumWorkers - 1
pvm_recv(888) {Receive result}
pvm_kill(<worker tid i>) {Terminate worker i}
display result
endfor
{Worker Mandelbrot algorithm.}
while (true)
pvm_recv(999) {Receive task}
result := MandelbrotCalculations(task) {Compute result}
pvm_send(<master tid>,888) {Send result to master}
endwhile
The master-slave example described above involves no communication
among the slaves. Most crowd computations of any complexity do need
to communicate among the computational processes; we illustrate the
structure of such applications using a node-only example for
matrix multiply using Cannon's algorithm [2]
(programming details
for a similar algorithm are given in another chapter).
The matrix-multiply example, shown
pictorially in Figure ![]() multiplies matrix subblocks locally, and
uses row-wise multicast of matrix A subblocks in conjunction
with column-wise shifts of matrix B subblocks.
multiplies matrix subblocks locally, and
uses row-wise multicast of matrix A subblocks in conjunction
with column-wise shifts of matrix B subblocks.
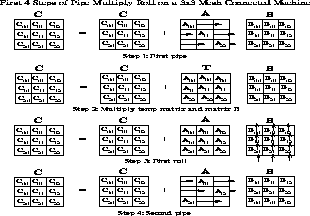
Figure: General crowd computation
{Matrix Multiplication Using Pipe-Multiply-Roll Algorithm}
{Processor 0 starts up other processes}
if (<my processor number> = 0) then
for i := 1 to MeshDimension*MeshDimension
pvm_spawn(<component name>, . .)
endfor
endif
forall processors Pij, 0 <= i,j < MeshDimension
for k := 0 to MeshDimension-1
{Pipe.}
if myrow = (mycolumn+k) mod MeshDimension
{Send A to all Pxy, x = myrow, y <> mycolumn}
pvm_mcast((Pxy, x = myrow, y <> mycolumn),999)
else
pvm_recv(999) {Receive A}
endif
{Multiply. Running totals maintained in C.}
Multiply(A,B,C)
{Roll.}
{Send B to Pxy, x = myrow-1, y = mycolumn}
pvm_send((Pxy, x = myrow-1, y = mycolumn),888)
pvm_recv(888) {Receive B}
endfor
endfor