The shared-memory architecture provides a very efficient medium for processes to exchange data. In our implementation, each task owns a shared buffer created with the shmget() system call. The task id is used as the ``key" to the shared segment. If the key is being used by another user, PVM will assign a different id to the task. A task communicates with other tasks by mapping their message buffers into its own memory space.
To enroll in PVM, the task first writes its Unix process id into pvmd's incoming box. It then looks for the assigned task id in pvmd's pid->TID table.
The message buffer is divided into pages, each of which holds one fragment
(Figure ![]() ).
PVM's page size can be a multiple of the system page size.
Each page has a header, which contains the lock and
the reference count.
The first few pages are used as the incoming box, while the rest of the pages
hold outgoing fragments (Figure
).
PVM's page size can be a multiple of the system page size.
Each page has a header, which contains the lock and
the reference count.
The first few pages are used as the incoming box, while the rest of the pages
hold outgoing fragments (Figure ![]() ). To send a message,
the task first packs the
message body into its buffer, then delivers the message header (which
contains the sender's TID and the location of the data) to the incoming
box of the intended recipient. When pvm_recv() is called, PVM checks
the incoming box, locates and unpacks the messages (if any), and
decreases the reference count so the space can be reused. If a task
is not able to deliver the header directly because the receiving box
is full, it will block until the other task is ready.
). To send a message,
the task first packs the
message body into its buffer, then delivers the message header (which
contains the sender's TID and the location of the data) to the incoming
box of the intended recipient. When pvm_recv() is called, PVM checks
the incoming box, locates and unpacks the messages (if any), and
decreases the reference count so the space can be reused. If a task
is not able to deliver the header directly because the receiving box
is full, it will block until the other task is ready.
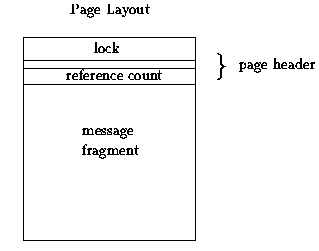
Figure: Structure of a PVM page
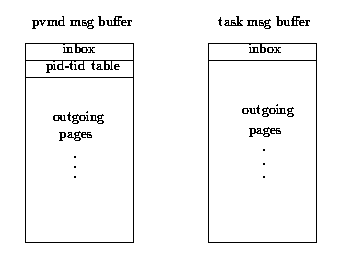
Figure: Structures of shared message buffers
Inevitably some overhead will be incurred when a message is packed into and unpacked from the buffer, as is the case with all other PVM implementations. If the buffer is full, then the data must first be copied into a temporary buffer in the process's private space and later transferred to the shared buffer.
Memory contention is usually not a problem. Each process has its own buffer, and each page of the buffer has its own lock. Only the page being written to is locked, and no process should be trying to read from this page because the header has not been sent out. Different processes can read from the same page without interfering with each other, so multicasting will be efficient (they do have to decrease the counter afterwards, resulting in some contention). The only time contention occurs is when two or more processes trying to deliver the message header to the same process at the same time. But since the header is very short (16 bytes), such contention should not cause any significant delay.
To minimize the possibility of page faults, PVM attempts to use only a small number of pages in the message buffer and recycle them as soon as they have been read by all intended recipients.
Once a task's buffer has been mapped, it will not be unmapped unless the system limits the number of mapped segments. This strategy saves time for any subsequent message exchanges with the same process.