This section describes the code necessary to build the BLAS's general matrix-matrix multiply using an L1 cache-contained matmul (hereafter referred to as the L1 matmul).
For our present discussion, it is enough to know that ATLAS has at its disposal highly optimized routines for doing matrix multiplies whose dimensions are chosen such that cache blocking is not required (i.e., the hand-written code discussed in this section deals with cache blocking; the generated/user supplied kernel assumes things fit into cache).
When the user calls GEMM, ATLAS must decide whether the problem
is large enough to tolerate copying the input matrices ![]() and
and ![]() .
If the matrices are large enough to support this
.
If the matrices are large enough to support this ![]() overhead, ATLAS will
copy
overhead, ATLAS will
copy ![]() and
and ![]() into block-major format. ATLAS's block-major format breaks up the input
matrices into contiguous blocks of a fixed size
into block-major format. ATLAS's block-major format breaks up the input
matrices into contiguous blocks of a fixed size ![]() , where
, where ![]() is chosen
in order to maximize L1 cache
reuse. Once in block-major format, the blocks are contiguous, which
eliminates TLB problems, minimizes cache thrashing and maximizes cache line
use. It also allows ATLAS to apply alpha (if alpha is not already one) to the
smaller of
is chosen
in order to maximize L1 cache
reuse. Once in block-major format, the blocks are contiguous, which
eliminates TLB problems, minimizes cache thrashing and maximizes cache line
use. It also allows ATLAS to apply alpha (if alpha is not already one) to the
smaller of ![]() or
or ![]() , thus minimizing this cost as well. Finally, the
package can use the copy to transform the problem to a particular transpose
setting, which for load and indexing optimization, is set so
A is copied to transposed form, and B is in normal (non-transposed) form.
This means our L1-cache contained code is of the form
, thus minimizing this cost as well. Finally, the
package can use the copy to transform the problem to a particular transpose
setting, which for load and indexing optimization, is set so
A is copied to transposed form, and B is in normal (non-transposed) form.
This means our L1-cache contained code is of the form
![]() ,
,
![]() ,
and
,
and
![]() ,
where all dimensions, including the non-contiguous stride, are known
to be
,
where all dimensions, including the non-contiguous stride, are known
to be ![]() . Knowing all of the dimensions of the loops allows for
arbitrary unrollings (i.e., if the instruction cache could support it, ATLAS
could unroll all loops completely, so that the L1 cache-contained multiply
had no loops at all). Further, when the code generator knows leading dimension
of the matrices (i.e., the row stride), all indexing can be done up front,
without the need for expensive integer or pointer computations.
. Knowing all of the dimensions of the loops allows for
arbitrary unrollings (i.e., if the instruction cache could support it, ATLAS
could unroll all loops completely, so that the L1 cache-contained multiply
had no loops at all). Further, when the code generator knows leading dimension
of the matrices (i.e., the row stride), all indexing can be done up front,
without the need for expensive integer or pointer computations.
If the matrices are too small, the ![]() data copy cost can actually
dominate the algorithm cost, even though the computation cost is
data copy cost can actually
dominate the algorithm cost, even though the computation cost is ![]() .
For these matrices, ATLAS will call an L1 matmul which operates on non-copied
matrices (i.e. directly on the user's operands). The non-copy L1 matmul
will generally not be as efficient as the copy L1 matmul; at this problem
size the main drawback is the additional pointer arithmetic required in order
to support the user-supplied leading dimension.
.
For these matrices, ATLAS will call an L1 matmul which operates on non-copied
matrices (i.e. directly on the user's operands). The non-copy L1 matmul
will generally not be as efficient as the copy L1 matmul; at this problem
size the main drawback is the additional pointer arithmetic required in order
to support the user-supplied leading dimension.
The choice of when a copy is dictated and when it is prohibitively expensive is an AEOS parameter; it turns out that this crossover point depends strongly both on the particular architecture, and the shape of the operands (matrix shape effectively sets limits on which matrix dimensions can enjoy cache reuse). To handle this problem, ATLAS simply compares the speed of the copy and non-copy L1 matmul for variously shaped matrices, varying the problem size until the copying provides a speedup (on some platforms, and with some shapes, this point is never reached). These crossover points are determined at install time, and then used to make this decision at runtime. Because it is the dominant case, this paper describes only the copied matmul algorithm in detail.
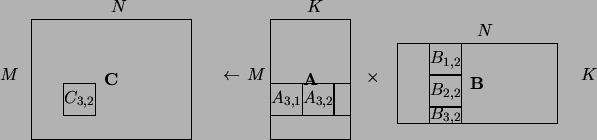
Figure 1 shows the necessary steps for computing a
![]() section of
section of ![]() using the L1 matmul.
using the L1 matmul.
More formally, the following actions are performed in order to
calculate the
![]() block
block ![]() , where
, where ![]() and
and ![]() are in
the range
are in
the range
![]() ,
,
![]() :
:
As this example demonstrates, if a given dimension is not a multiple of
the L1 blocking factor ![]() , partial blocks results. ATLAS has special
routines that handle cases where one or more dimension is less than
, partial blocks results. ATLAS has special
routines that handle cases where one or more dimension is less than ![]() ;
these routines are referred to as cleanup codes.
;
these routines are referred to as cleanup codes.