As convergence takes place, the subdiagonals of ![]() tend to zero
and the most desired eigenvalue approximations appear as eigenvalues
of the leading
tend to zero
and the most desired eigenvalue approximations appear as eigenvalues
of the leading ![]() block of
block of ![]() in a Schur decomposition of
in a Schur decomposition of ![]() .
The basis vectors
.
The basis vectors ![]() tend to orthogonal Schur vectors.
tend to orthogonal Schur vectors.
An alternate interpretation stems from the fact that
each of these shift cycles results in the implicit application of a
polynomial in ![]() of degree
of degree ![]() to
the starting vector.
v_1 (A) v_1 with () = _j=1^p (- _j ).
The roots of this polynomial are the shifts used in
the QR process and these may be selected to
enhance components of the starting vector in the direction of eigenvectors
corresponding to desired eigenvalues and damp the components in unwanted
directions. Of course, this is desirable because it forces
the starting vector into an invariant subspace associated with the
desired eigenvalues. This in turn forces
to
the starting vector.
v_1 (A) v_1 with () = _j=1^p (- _j ).
The roots of this polynomial are the shifts used in
the QR process and these may be selected to
enhance components of the starting vector in the direction of eigenvectors
corresponding to desired eigenvalues and damp the components in unwanted
directions. Of course, this is desirable because it forces
the starting vector into an invariant subspace associated with the
desired eigenvalues. This in turn forces ![]() to become small and hence
convergence results. Full details may be found in [419].
to become small and hence
convergence results. Full details may be found in [419].
There is a fairly straightforward intuitive explanation
of how this repeated updating of the starting
vector ![]() through implicit restarting might lead to convergence.
If
through implicit restarting might lead to convergence.
If ![]() is expressed as a linear combination of eigenvectors
is expressed as a linear combination of eigenvectors ![]() of
of ![]() , then
, then
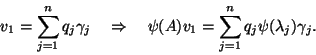
It is worth noting that if ![]() then
then ![]() and this
iteration is precisely
the same as the implicitly shifted QR iteration. Even for
and this
iteration is precisely
the same as the implicitly shifted QR iteration. Even for ![]() , the
first
, the
first ![]() columns of
columns of ![]() and the Hessenberg submatrix
and the Hessenberg submatrix ![]() are
mathematically equivalent to the matrices that would appear in the
full implicitly shifted QR iteration using the same shifts
are
mathematically equivalent to the matrices that would appear in the
full implicitly shifted QR iteration using the same shifts ![]() In this sense, the implicitly restarted Arnoldi method may be viewed
as a truncation of the implicitly shifted QR iteration.
The fundamental difference is that the standard implicitly shifted QR
iteration
selects shifts to drive subdiagonal elements of
In this sense, the implicitly restarted Arnoldi method may be viewed
as a truncation of the implicitly shifted QR iteration.
The fundamental difference is that the standard implicitly shifted QR
iteration
selects shifts to drive subdiagonal elements of ![]() to zero from the
bottom up while the shift selection in the implicitly restarted Arnoldi method
is made to drive subdiagonal elements of
to zero from the
bottom up while the shift selection in the implicitly restarted Arnoldi method
is made to drive subdiagonal elements of ![]() to zero from the top down.
Shifted power-method-like convergence will be obtained.
to zero from the top down.
Shifted power-method-like convergence will be obtained.
When the exact shift strategy is used, implicit restarting can be viewed
both as a means to damp unwanted components from the starting vector
and also as directly forcing the starting vector to be a
linear combination of wanted eigenvectors.
See [419] for information on the convergence of
IRAM and [22,421] for other possible shift strategies for
Hermitian ![]() The reader is referred to [292,333] for studies
comparing implicit restarting with other schemes.
The reader is referred to [292,333] for studies
comparing implicit restarting with other schemes.