Alternative Approaches to Libraries




Next: References
Up: Future Directions
Previous: Future addition to
Traditionally, large, general-purpose mathematical software libraries
on uniprocessors and shared memory machines have tried to hide much
of the complexity of data structures and performance issues from the
user. For example, the LAPACK project incorporates parallelism in the
Level 3 BLAS, where it is not directly visible to the user.
Unfortunately, it is not possible to hide these details as neatly on
distributed memory machines. Currently, the data structures and data
decomposition must be specified by the user, and it may be necessary to
explicitly transform these structures in between calls to different
library routines. These deficiencies in the conventional user interface
have prompted extensive discussion of alternative approaches for
scalable parallel software libraries of the future. Here are some
possibilities.
- Traditional function library (i.e., minimum possible change to
the status quo in going from serial to parallel environment). This
will allow one to protect the programming investment that has been
made. More aggressive use of performance models may permit us to
choose the best layout and redistribute the input data structure
automatically. This is attractive for dense linear algebra since
for large problems the
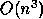 floating point operations will
dominate the
floating point operations will
dominate the 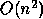 cost of redistribution.
cost of redistribution.
- Reactive servers on the network. A user would be able to send
a computational problem to a server that was specialized in dealing
with the problem. This fits well with the concepts of a networked,
heterogeneous computing environment with various specialized hardware
resources (or even the heterogeneous partitioning of a single
homogeneous parallel machine). Again, this is attractive for
dense linear algebra since flops are performed on a
data structure of size .
- Interactive environments like Matlab or Mathematica, perhaps
with ``expert'' drivers (i.e. knowledge-based systems) for special
domains, such as structural analysis. Such environments have proven
to be especially attractive for rapid prototyping of new algorithms
and systems that may subsequently be implemented in a more customized
manner for higher performance. With the growing popularity of the
many integrated packages based on this idea, this approach would
provide an interactive, graphical interface for specifying and
solving scientific problems. Both the algorithms and data structures
are hidden from the user, because the package itself is responsible
for storing and retrieving the problem data in an efficient,
distributed manner. In a heterogeneous networked environment,
such interfaces could provide seamless access to computational
engines that would be invoked selectively for different parts of
the user's computation according to which machine is most appropriate
for a particular subproblem.
- Reusable templates (i.e., users adapt ``source code'' to their
particular applications). A template is a description of a general
algorithm rather than the executable object code or the source code
more commonly found in a conventional software library. Nevertheless,
although templates use generic versions of key data structures, they
offer whatever degree of customization the user may desire. We have
constructed such a set of template for interactive linear system
solvers, and are currently constructing one for eigenvalue problems.
Next: References
Up: Future Directions
Previous: Future addition to
Antoine Petitet
Fri Mar 31 13:01:26 EST 1995