


In Figure 1 already one subclass of this type of machines was shown. In fact, the single-processor vector machine discussed there was a special case of a more general type. The figure shows that more than one FPU and/or VPU may be possible in one system.
The main problem one is confronted with in shared-memory systems is that of the connection of the CPUs to each other and to the memory. As more CPUs are added, the collective bandwidth to the memory ideally should increase linearly with the number of processors, while each processor should preferably communicate directly with all others without the much slower alternative of having to use the memory in an intermediate stage. Unfortunately, full interconnection is quite costly, growing with O(n²) while increasing the number of processors with O(n). So, various alternatives have been tried. Figure 4 shows some of the interconnection structures that are (and have been) used.
As can be seen from the figure, a crossbar uses n²
connections, an Ω-network uses nlog2n
connections while, with the central bus, there is only one connection.
This is reflected in the use of each connection path for the different
types of interconnections: for a crossbar each datapath is direct and
does not have to be shared with other elements. In case of the Ω-network
there are log
The bus connection is the least expensive solution, but it has the obvious
drawback that bus contention may occur thus slowing down the computations.
Various intricate strategies have been devised using caches associated with the
CPUs to minimise the bus traffic. This leads however to a more complicated bus
structure which raises the costs. In practice it has proved to be very hard to
design buses that are fast enough, especially where the speed of the processors
have been increasing very quickly and it imposes an upper bound on the number
of processors thus connected that in practice appears not to exceed a number of
10-20. In 1992, a new standard (IEEE P896) for a fast bus to connect either
internal system components or to external systems has been defined. This bus,
called the Scalable Coherent Interface (SCI) should provide a point-to-point
bandwidth of 200-1,000 Mbyte/s. It is in fact used in the HP Exemplar systems,
but also within a cluster of workstations as offered by SCALI. The SCI is much
more than a simple bus and it can act as the hardware network framework for
distributed computing, see [20].
A multi-stage crossbar is a network with a logarithmic complexity and
it has a structure which is situated somewhere in between a bus and a
crossbar with respect to potential capacity and costs. The Ω-network is
as depicted in Figure 4 is an example.
Commercially available machines like the IBM eServer p690, the SGI
Origin3000, and the late Cenju-4 use such a network structure, but a number
of experimental machines also have used this or a similar kind of
interconnection. The BBN TC2000 that acted as a virtual shared-memory
MIMD system used an analogous type of network (a Butterfly-network) and
it is quite conceivable that new machines may use it, especially as the
number of processors grows. For a large number of processors the
nlog2n connections quickly become more
attractive than the n² used in crossbars. Of course, the
switches at the intermediate levels should be sufficiently fast to cope
with the bandwidth required. Obviously, not only the structure
but also the width of the links between the processors is
important: a network using 16-bit parallel links will have a bandwidth
which is 16 times higher than a network with the same topology
implemented with serial links.
In all present-day multi-processor vectorprocessors crossbars are used.
This is still feasible because the maximum number of processors in a
system is still rather small (32 at most presently). When the number of
processors would increase, however, technological problems might arise.
Not only it becomes harder to build a crossbar of sufficient speed for
the larger numbers of processors, the processors themselves generally
also increase in speed individually, doubling the problems of making
the speed of the crossbar match that of the bandwidth required by the
processors.
Whichever network is used, the type of processors in principle could be
arbitrary for any topology. In practice, however, bus structured
machines do not have vector processors as the speeds of these would
grossly mismatch with any bus that could be constructed with reasonable
costs. All available bus-oriented systems use RISC processors. The
local caches of the processors can sometimes alleviate the bandwidth
problem if the data access can be satisfied by the caches thus avoiding
references to the memory.
The systems discussed in this subsection are of the MIMD type and
therefore different tasks may run on different processors
simultaneously. In many cases synchronisation between tasks is required
and again the interconnection structure is here very important. Most
vectorprocessors employ special communication registers within the CPUs
by which they can communicate directly with the other CPUs they have to
synchronise with. The systems may also synchronise via the shared
memory. Generally, this is much slower but may still be acceptable when
the synchronisation occurs relatively seldom. Of course in bus-based
systems communication also has to be done via a bus. This bus is
mostly separated from the databus to assure a maximum speed for the
synchronisation.
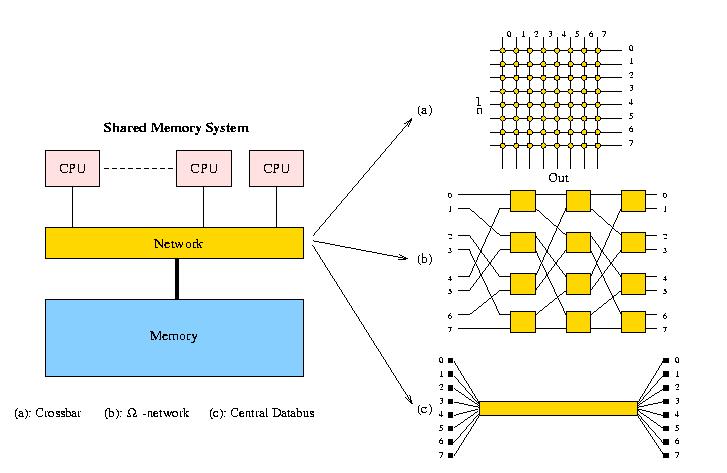
Figure 4: Some examples of interconnection structures used in
shared-memory MIMD systems.
Next:
Distributed-memory MIMD machines
Up:
The Main Architectural Classes
Previous:
Distributed-memory SIMD machines
Aad van der Steen
Thu Oct 7 14:19:54 CEST 2004