


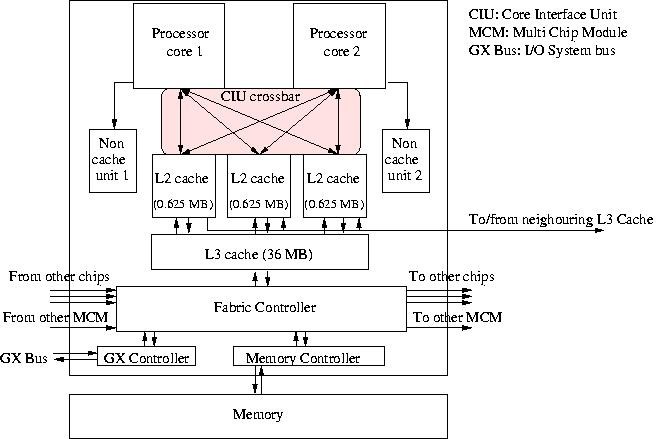
As remarked in section IBM POWER4+ the POWER5 chip will replace the POWER4+ in the near future and we therefore present some features of this chip here. Presently it runs at the same speed as the fastest POWER4+: 1.9 GHz. Like the POWER4(+) the POWER5 has two CPUs on a chip. These CPU cores have a similar structure as shown in Figure 10a. There is however a significant difference between the chips of the POWER4 and the POWER5. Because of the higher density on the chip (the POWER5 is built in 130 nm technology instead of 180 nm used for the POWER4+) more devices could be placed on the chip and they could also be enlarged. First the L2 caches of two neighbouring chips are connected and the L3 caches are directly connected to the L2 caches. Both are larger than their respective counterparts of the POWER4: 1.875 MB against 1.5 MB for the L2 cache and 36 MB against 32 MB for the L3 cache. In addition the speed of the L3 cache has gone up from about 120 cycles to 80 cycles. Also the associativity of the caches has improved: from 2-way to 4-way for the L1 cache, from 8-way to 10-way for the L2 cache, and from 8 to 12-way for the L3 cache. A big difference is also the improved bandwidth from memory to the chip: it has increased from 4 GB/s for the POWER4+ to $\approx$ 16 GB/s for the POWER5. We show the embedding of the POWER5 in Figure 11.
The better cache characteristics leads to less waiting time for regular data
access: evaluation of a high order polynomial and matrix-matrix multiplication
attain 90% or better of the peak performance while this is 65--75% on the
POWER4+ chip. There is another feature of the POWER5 that does not help for
regular data access but which can be of benefit for programs where the data
access is not so regular: Simultaneous Multithreading (SMT). The POWER5 CPUs
are able to keep two process threads at work at the same time. The functional
units get instructions for the functional units from any of the two threads
whichever is able to fill a slot in an instruction word that will be issued to
the functional units. In this way a larger fraction of the functional units can
be kept busy, improving the overall efficiency. For very regular computations
single thread (ST) mode may be better because in SMT mode the two threads
compete for entries in the caches which may lead to trashing in the case of
regular data access. Note that SMT is somewhat different from the ``normal''
way of multi-threading. In this case a thread that stalls for some reason is
stopped and replaced by another process thread that is awoken at that time. Of
course this takes some time that must be compensated for by the thread that has
taken over. This means that the second thread must be active for a fair amount
of cycles (preferably a few hundred cycles at least). SMT does not have this
drawback but scheduling the instructions of both threads is quite complicated.