
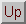


| Machine type | Processor array |
|---|---|
| Models | MP1101, MP1102, MP1104, MP1208, MP1216 |
| Front-end | DECstation 5000 or DEC VAX |
| Operating system | Internal OS transparent to the user, Ultrix or VMS on front-end |
| Connection structure | 2-D mesh, crossbar (see remarks) |
| Compilers | MPL: (C with extensions), MPF: (Fortran 90-like with extensions) |
System parameters:
| Model | MP1101 | MP1102 | MP1104 | MP1208 | MP1216 |
|---|---|---|---|---|---|
| Clock cycle | 83 ns | 83 ns | 83 ns | 83 ns | 83 ns |
| No. of processors | 1024 | 2048 | 4096 | 8192 | 16384 |
| Theor. peak performance | |||||
| Per proc. (Mflop/s ) | 0.034 | 0.034 | 0.034 | 0.034 | 0.034 |
| Mop/s (32-bit) | 1600 | 3200 | 6400 | 13000 | 26000 |
| Mop/s (64-bit) | 800 | 1600 | 3200 | 6400 | 13000 |
| Mflop/s (32-bit) | 75 | 150 | 300 | 600 | 1200 |
| Mflop/s (64-bit) | 34 | 69 | 138 | 275 | 550 |
| Program memory | 1-4MB | 1-4MB | 1-4MB | 1-4MB | 1-4MB |
| Data memory | 16-64MB | 32-128MB | 64-256MB | 128-512MB | 256-1GB |
| Int. comm. speed | |||||
| Via Xnet (n. neighbour) | 1.4 GB/s | 2.8 GB/s | 5.7 GB/s | 11.5 GB/s | 23.0 GB/s |
| Via global router | 80 MB/s | 160 MB/s | 320 MB/s | 640 MB/s | 1.28 GB/s |
Remarks:
The Processing Elements (PEs) of the MP-1 are more intricate than those from the CPP Gamma II. Each PE contains a 4-bit parallel Arithmetic/Logic Unit together with a 1-bit functional unit, a 16-bit exponent unit and a 64-bit mantissa unit. These units may be operated separately or in concord (e.g., for floating-point calculations). Because of the hardware implementation of the PEs, only 1-, 8-, 16-, 32-, and 64-bit data types are allowed.
Unlike on the CPP Gamma II, on the MP-1 it is possible to address data items in the data memories indirectly. This greatly facilitates manipulation of matrix objects indexed through an index matrix.
One type of interconnection of the PEs is a 2-D rectangular mesh (with wrap-around). This is however implemented by connecting the PEs diagonally via 3-way switches. As the setting of the switches only takes 1 cycle, this means that every PE can reach it 8 surrounding neighbours in 1 cycle. For more general routing schemes a Global Router is available. This acts, in principle, as a three-stage crossbar. PEs are arranged in clusters of 4×4, which connect to other clusters through the first level of the crossbar. All clusters connect via an intermediate stage to the target stage (again at cluster level). The ports from the clusters are multiplexed to the individual PEs within a cluster. As this type of communication is fairly intricate, it is much slower than via the Xnet (see system parameter list above).
As with the CPP Gamma II, there are provisions for connecting a frame buffer and/or disks directly to the MP-1. Also like the Gamma II, the MP-1 is essentially a single-user machine, that is, only one user at a time can have a task on the MP-1. Of course, tasks can be scheduled via a multi-user interface on the front-end system.
The MP-1 features a very nice X-window based programming environment, MPPE, which integrates an interactive source debugger, a profiler, and output windows in one environment.
Measured Performances: In [4] the solution of a full linear system was reported on a 16384 PE machine with a speed of 440 Mflop/s. The same report estimated the peak performance to be 580 Mflop/s in 64-bit precision.