The Origin2000 is a so-called Non-Uniform Memory Access (NUMA) parallel system which means that the time to fetch or store data from/to the memory may vary with the particular CPU and storage location of the data that are required or produced by that CPU. The machines employs MIPS R10000 processors with 32 KB primary instruction and data caches. On this machine all tests were conducted with the MIPSPRO f77 compiler, version 7.20 with options -O3 -64 -OPT:IEEE arithmetic=3:roundoff=3. The secondary cache was 4 MB on our test system. The system will usually be used as a shared-memory system in which all CPUs can access all of the memory as a logical single entity. However, this is not necessary: the machines can also be viewed as a distributed memory system and various message passing libraries like MPI is (and the Cray shmem library shortly will be) available. So, the system can be used with various programming models each of which may have its own advantages in various situations.
The Cray T3E on which we generated our results contains DEC Alpha 21164 processors with a clock cycle of 3.3 ns. The primary data cache and instruction caches are both 8 KB while the secondary cache is 96 KB. On the T3E we used the f90 compiler, version 3.0.0.1 with options -O3 -dp. On the T3E are stream buffers available that assist in prefetching fixed-stride data and that may speed up both computation and communication. The results in this paper all are generated with the stream buffers on except for the measurement of the point-to-point communication speed where this speed was measured both with streams on and off to show the influence. The computational nodes are connected by a fast 3-D torus network. The T3E was only used as a distributed memory message passing machine. Both the use of the Cray shmem library and MPI are possible. We only quote MPI results, however. For a more detailed description of the Origin2000 and the Cray T3E systems one is referred to [9, 13].
This paper has the following structure: Section 2 contains a short description of the EuroBen Benchmark. We present the structure of the benchmark, give reasons for its structure and what we hope to learn from its results.
In section 3 a selection of the results of the benchmark is presented. We discuss these results in the light of the knowledge of the architecture. Both single CPU results and parallel results for a selection of programs are given. The EuroBen benchmark originally was written for shared-memory systems, however, a few programs are also available as distributed-memory message passing codes. Comparing these different programming models is quite interesting. Where relevant we compare the outcomes of the benchmark on the Origin2000 with those of the Cray T3E.
The last section summarises the results of the previous one and we draw conclusions as to our findings with regard to the performance of the Origin 2000.
The results in this paper have been generated using Origin2000 systems that run at a clock speed of 5.13 ns (195 MHz). There are models of the Origin2000 that run at a speed of 5.56 ns (180 MHz). The results from the faster machine will carry over directly to the slower model.
2. The EuroBen Benchmark
The programs in the EuroBen Benchmark range from very simple to complete algorithms that are important in certain application areas. The simple programs give basic information on the performance of operations, intrinsic functions, etc., in order to identify the strong and weak points of a machine. When one wants to extract more information one should conduct the next level of tests which contains simple but frequently used algorithms like FFTs, random number generation, etc. So, a graded approach is used to collect the necessary information. When one wants more information one has to run more modules. The results will generally become less easy interpretable as the level of complication rises but they will still be comparable for different machines of similar architecture. In this stage the degree of similarity is already known from the hardware and software characteristics as described above. As yet all modules are written in Fortran 77 and at least 64-bit floating-point arithmetic is required.
The structure of the benchmark is inherited from an earlier one [10] but it has been modified considerably since its first version and improved by programs of some of the EuroBen founders, Armin Friedli (measuring speed and accuracy of intrinsic functions) and Roger Hockney (measurement of the parameter f 1/2 , for an explanation of this parameter see [4].
2.1 Contents of module 1
The contents of the first module as distributed in the current version (version 3.2) are:
mod1ac) A test program for basic operations.
2.2 Contents of module 2
In the second module simple basic algorithms are brought together. These algorithms are frequently employed in typical numerical applications like optimisation, digital signal analysis, etc.. For many algorithms in this module vendors make library routines available because of their importance. The library routines should be compared with the algorithms given here. The second module contains the following programs:
mod2a) A full matrix-vector product for n = 25, 50, 100, 200, 300, 500.
2.3 Contents of module 3
In the third module more elaborate algorithms have been collected. For the greater part, they contain algorithms already present in some form in module 1 and 2 but they more represent classes of computational problems encountered in scientific applications. This includes explicit I/O-schemes for very large problems as opposed to automatic handling by virtual memory operating systems. The contents of the third module are:
mod3a) Very large, very sparse matrix-vector multiplication.
One should refrain from tuning the code beyond the necessary changes to employ the available parallelism in order to obtain results that are comparable with those from other machines. We believe that most of the results found from module 3 can be interpreted with reasonable completeness with help of the knowledge provided by the necessary machine information and the former two modules.
2.4 Time dependency of the benchmark
The contents of the benchmark set is not static. So, new versions are developed if required. For instance, various programs in module 2 and module 3 relied on BLAS, LINPACK, and EISPACK as widely distributed and accepted standard software. However, these packages presently often have been replaced by more modern software like level 2 and level 3 BLAS, and LAPACK. These developments have had their impact on the contents of the EuroBen benchmark. Also, new algorithms have to be introduced because of their growing importance. For instance a Discrete Wavelet Transform will be introduced as program mod2g in the next release of the benchmark.
2.5 Distributed memory programs
The EuroBen benchmark was originally conceived for shared-memory systems. However, the proportion of DM-MIMD systems has grown steadily since the time of conception. Although also on these machines nowadays often a shared-memory program model is offered (Cray T3D, HP/Convex Exemplar, SGI Origin 2000), the importance of benchmarking DM-MIMD systems with a message-passing programming model is quite high.
Presently, only for a few programs in the EuroBen suite message-passing implementations are available: gmxv and disfft which correspond to the shared memory programs mod2a and mod2f, respectively. Program disfft is implemented in a 2-D product form using the same radix-4 algorithm as program mod2f. In addition programs mod1h and dddot are provided. The first program measures basic point-to-point communication speed (bandwidth and latency); the second one tests three implementations of a distributed dotproduct. It is important in that it gives insight in the quality of available reduction and broadcast operations and also tests the influence of concentrating many send and receive buffers on one processor.
3 Benchmark results
3.1 Results of module 1
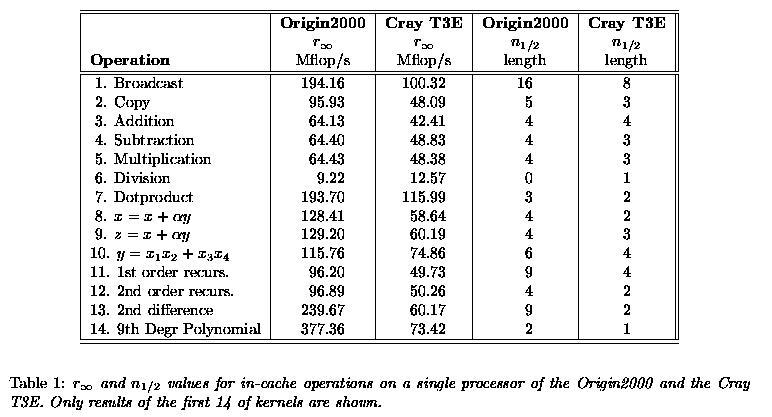
We first present the results for basic operations as measured with program mod1ac. In Table 1 the n1/2 and rinf values on one processor of the Origin2000 and the Cray T3E are given for operations of which the operands are loaded from the primary cache.
We only show the first 14 of the 31 kernels. Kernel 15--31 perform operations that are largely identical with kernels 1--14 except that odd and even strides and index arrays are employed. The results found with these latter kernels were so similar to the first ones that we do not give them here. However, this behaviour is markedly different from that of vectorprocessor-based systems where usually a significant difference in speed is found.
Table 2 list the results for the same kernels, however now with the operations from memory. In this table Origin2000 Cray T3E
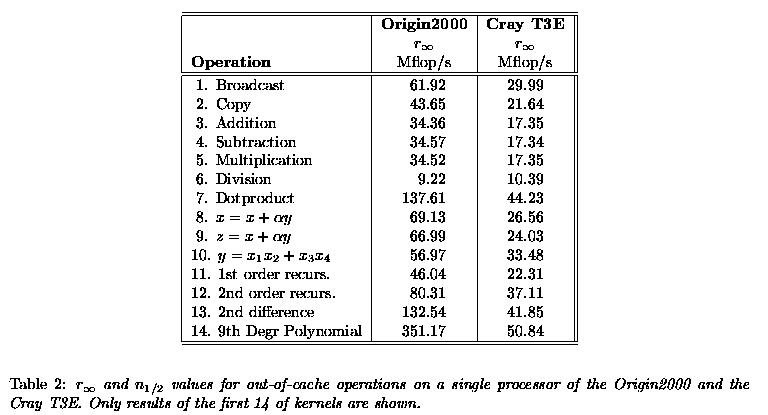
we left the n1/2 values out because they all were negligible. The first to remark is that, although the clock frequency of the R10000 processor is lower than that of the Alpha 21164 (195 vs. 300 MHz), the Origin2000 processor is always faster, except for the in-cache division. This exception is caused by the fact that division in the R10000 is performed by a so-called secondary floating-point unit that is not pipelined at all. For the dyadic operations, +, -, and x the Origin2000 approaches a speed of 65 Mflop/s which is consistent with loading/storing one operand/cycle in the in-cache situation. The R10000 should be able to load/store two 64-bit operands/cycle, so only half of the maximum bandwidth is used. The 21164 processor uses less than 50% of the bandwidth that ships one operand/cycle for these operations. The situation for out-of-memory operations is worse: for most operations the performance roughly drops by a factor of 2 for the Origin2000 while it decreases mostly by a factor of 2--3 on the T3E. The dyadic out-of-memory operations suggest processor-to-memory bandwidths of 828 and 416 MB/s for the Origin2000 and T3E, respectively. The speed given for kernels 7--10 in Table 2 are consistent with these bandwidths.
Clearly, no optimisation is done for the dyadic operations on the T3E. A hand-coded single unrolling of kernels 3--5 yielded rinf values of about 70 Mflop/s for in-cache operation (while the n1/2 values were approximately the same). The speeds for out-of-cache operations are not notably affected as these are completely determined by the low processor-memory bandwidth.
Kernel 14, the evaluation of a 9th degree polynomial has a very high reuse of operands in the registers and should consequently nearly attain the Theoretical Peak Performance at the respective systems (these values are 390 and 600 Mflop/s for the Origin2000 and the T3E, respectively). This turns out to be true for the Origin2000 but hardly so for the T3E: both with in-cache and out-of-cache operation slightly more than 10% of the Theoretical Peak Performance is observed. As yet, we have no explanation for this behaviour.
3.1.1 mod1ac in parallel
As the Origin2000 can be used as a SM-MIMD system it is simple to run
program mod1ac in parallel. In Figure 1 the rinf
values for 1, 4, and 10
processors for the first 14 kernels are displayed.
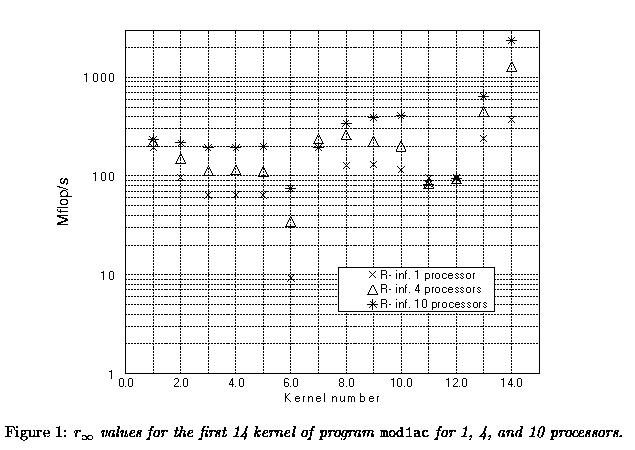
Kernel 7, 11, and 12 do not benefit much from parallelisation. In fact, the compiler uses heuristics to determine whether parallelisation is worthwhile. The choices made for these estimations seem to work: either a kernel is parallelised and benefits from it or the loop is not parallelised. We did not observe kernels that decreased in performance due to parallelisation overhead. However, the overhead is clearly not negligible as can be seen from the values in Figure 1. Another indicator for the parallelisation overhead were the corresponding n1/2 values. These ranged to lengths of 200--500 on 4 processors and to 800--1400 on 10 processors.
Note that for kernel 7, the dotproduct, there is a slight improvement from 1 to 4 processors but the kernel is not parallelised on 10 processors due to too little work to be done in the loop. Kernels 11 and 12 are first and second order recurrences. Naturally, these are not parallelised.
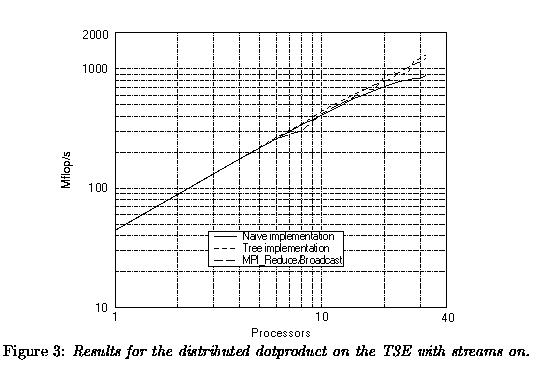
3.1.2 The distributed dotproduct
On both machines we executed the program dddot which contains three
different implementations of a distributed- dotproduct
of length 1,000,000: a "naive" implementation, a Fortran-coded tree
implementation and using MPI Reduce/ Broadcast. In the naive implementation
all partial sums are sent to one processor to assemble the global
sum. The global sum is broadcast from this processor to all others again.
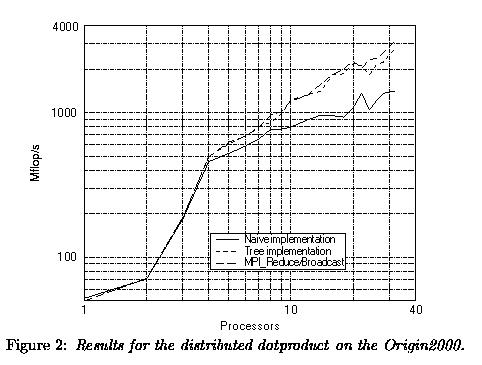
The results of this program are given in Figures 2 and 3 respectively.
The Figures 2 and 3 show that on both machines there is not much
difference between the tree implementation and using the MPI Reduce/ Broadcast
routines. As may be expected the naive implementation performs worse on
both systems. In absolute speed the Origin2000 is about 2 times faster
than the T3E. This is not in line with the out-of-cache results found earlier
with program mod1ac where the dotproduct is more than 4 times faster. The
relatively better performance must be ascribed to the communication
that seems more efficient on the T3E as is apparent from the per
node performance: on the Origin2000 it decreases from 138 to 99 Mflop/s
on 32 processors while on the T3E this decrease is only from 44 to
41 Mflop/s on 32 processors.
3.1.3 Results for mod1e/f
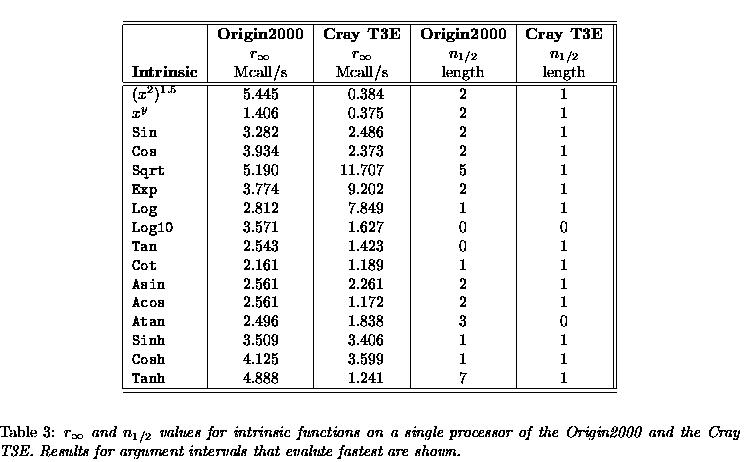
Program mod1f measures the speed of the most important intrinsic functions for all ranges of interest while mod1e tests their correctness and precision. For both machines the precision as tested with mod1e was acceptable. The results of program mod1f are given in Table 3. We only show the result for the argument intervals that are evaluated fastest. However, there is not much difference in speed between the various argument intervals. Also, the length of the argument vector has not much influence: in-cache and out-of-cache results hardly differ in speed.
As can be seen from Table 3 in almost all cases the Origin2000 is faster by a factor of 1.5--4. There are some notable exceptions: (x 2 ) 1:5 is evaluated almost 15 times faster on the Origin2000 and both the Sqrt and Exp functions are significantly faster on the T3E. For the Sqrt this can be explained by the fact that a non-pipelined secondary floating-point unit is employed to compute square root values on the Origin2000 which is relatively slow. For the Exp function there is no such explanation.
3.1.4 Results for mod1g
Program mod1g computes the cost of memory references through the f 1/2 parameter (see [4]). For the T3E f 1/2 is 0.4452 flop/mref with a rinf (rhat) of 77.08 Mflop/s. For the Origin2000 these figures are 0.7323 flop/mref and 413.99 Mflop/s, respectively. The values given here are measured for in-cache operation. Though the f 1/2 value of the Origin2000 is almost two times higher, this is more than compensated for by the higher rinf (rhat).
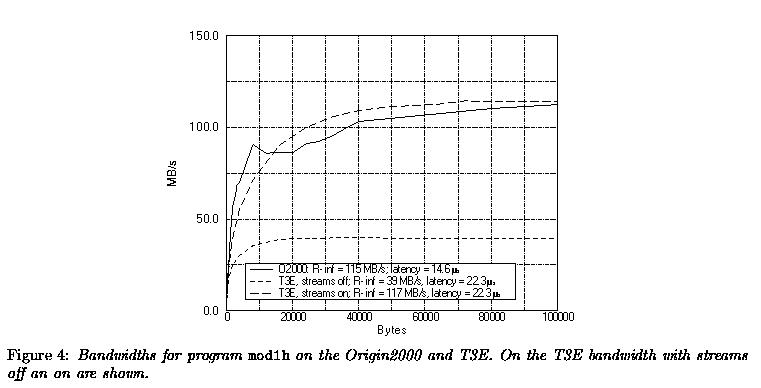
3.1.5 Results for mod1h
mod1h is a simple point-to-point communication measurement program that measures the bandwidth and latency for a 1-hop communication. This is done by a ping-pong procedure using the MPI Send and MPI Recv routines, much like that in the COMMS1 program from the Parkbench Benchmark [5]. However, for the computation of the latencies only short messages were used. Firstly, because for short messages the latency has a large effect and so is more important for the effective bandwidth with which such a short message is sent. Secondly, because the buffering strategy is changed with the message length for most MPI implementations. This is also the case on the Origin2000 and the T3E. Therefore, only messages up to 400 bytes were used to determine the latencies. The latencies found were 22.3 and 22.2 micro-secs for the T3E with the stream buffer off and on respectively. The standard errors in these values were 1.5% and 2.9%. On the Origin2000 the latency for small messages was only 14.6 micro-secs with a standard error of 3.3%.
On both the Origin2000 and the T3E MPI was used for passing the messages.
We do not yet have shmem library results because this library
was not yet available on the Origin2000 . In Figure 4 the results for both
machines are shown. For the T3E the bandwidths both with the stream
buffers off and on were measured. As already seen with the distributed
dot product and as also will be apparent from program mod2a
and the distributed FFT program, the values as given in Figure 4
do not reflect the actual situation in algorithms: although the rcinf
bandwidth for the Origin2000 is about the same and the latency is 1.7 times
lower, the T3E scales mostly better than the Origin2000 . This is
due to MPI implementation on the Origin2000: as yet at least one
extra buffer copy is required in passing a message. Currently SGI is working
on a better implementation.
The two-parameter model for the communication, represented by rcinf
and nc1/2, does not fit well with the observed
results. This is due to the different buffer strategies that are employed
in the MPI Send/ Recv routines depending on the lengths of the messages
mentioned earlier.
3.2 Results of module 2
For reasons of briefness we present a selection of results of module 2. We mainly concentrate on the programs of which we have shared-memory and distributed-memory parallel results. For the Origin2000 this allows us to assess the overheads associated with the different programming models and, in addition, we can compare the distributed-memory version results with those from the T3E.
3.2.1 Results of mod2a
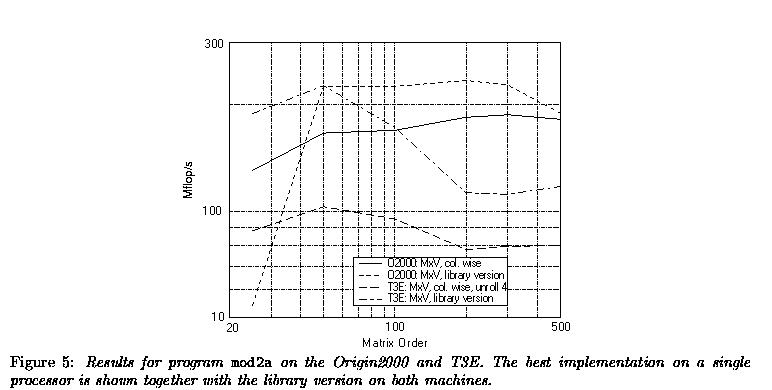
Program mod2a performs a full matrix-vector multiplication (transposed and not transposed). Four different implementations are executed. Moreover, on both the Origin2000 and the T3E the library routines as provided by SGI was also run. In Figure 5 the best results on a single processor for the not-transposed case are given on the Origin2000 and the T3E (a 4 times unrolled column-wise version). In addition, the result for the SGI's DGEMV libary version are given.
Figure 5 shows that, except for the smallest problem order, the library version on the Origin2000 is significantly faster than the Fortran 77 coded version as (one might hope): about 220 vs. 180 Mflop/s. For the T3E the primary cache size (8 KB) is already exceeded at a problem size if n = 50. At n = 200 the speed is completely determined by processor-to-memory bandwidth. This results in a speed of roughly 45 Mflop/s. The library version also experiences a performance decrease after n = 50 but always performs much better than the Fortran version. At n = 500 the performance is still about 120 Mflop/s. On the
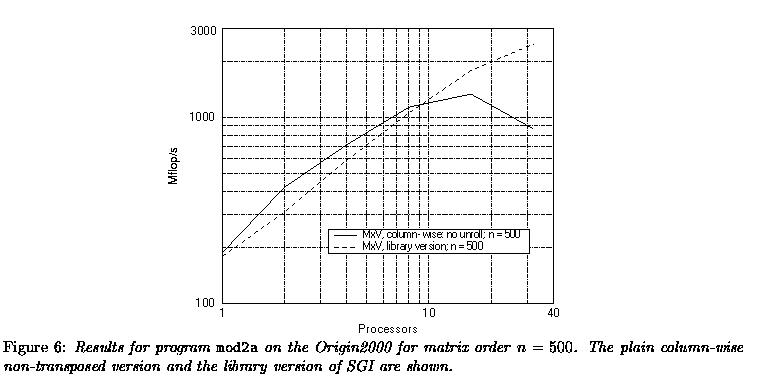
Origin2000 the same program has been executed as a shared-memory parallel program. The results for matrix order n = 500, are displayed for one of the Fortran 77 versions and the SGI library version in Figure 6.
Figure 6 shows that the Fortran 77 is faster up to 8 processors. Above this number of processors the library routine clearly is more efficient. Another point to remark is that the plain column-wise version is now significantly faster than the 4 times unrolled version, sometimes by a factor of 4. The parallelising software seems not to agree well with the unrolling of the loops.
For the Fortran version the speedup levels off at 16 processors: it
is still 7.1 but above this number of processors the synchronisation
overhead together with the decreased amount of work per processor cause
a performance drop: the speedup at 32 processors is only 4.6. By constrast,
the library version still scales reasonably well at 32 processors: the
speedup is 13.8 in this case.
3.2.2 Distributed memory results for mod2a
The message passing counterpart of mod2a is the program gmxv. This program was run on the Origin2000 and the T3E. The results of the fastest implementations for both machines are shown for a matrix order n = 512 in Figure 7.
It is instructive to compare the speedup of shared-memory programming model with that of the distributed- memory implementation on the Origin2000. One should realise that, although the system image of an Origin2000 is that of a shared-memory system, the data are physically distributed and that non-uniform memory transactions occur. In addition, a certain overhead is incurred in keeping the caches coherent of the processors involved in the computation. The net result of this is that on 32 processors the in the shared memory model is 13.8 (using the library routine), while in the message passing model this speedup is 31.6 compared with the best single processor result. So, one has to pay a price for using the shared memory model. This price may however not be too high in many applications.
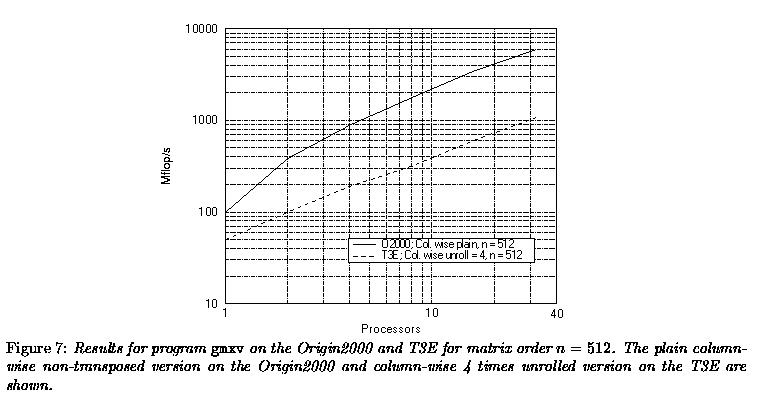
The scaling on the T3E is excellent: a speedup of 6.36 on 8 processors
and of 21.6 on 32 processors is found. On has to take into account
that even on 32 processors the primary cache size is still exceeded
by more than a factor of 8 and, consequently, no speedup due to in-cache
operation will occur. As in the non-transposed case no data have
to be exchanged between the processors, less than perfect speedup is to
be ascribed to the setup of the communication network and the synchronisations
at the beginning and end of the computations.
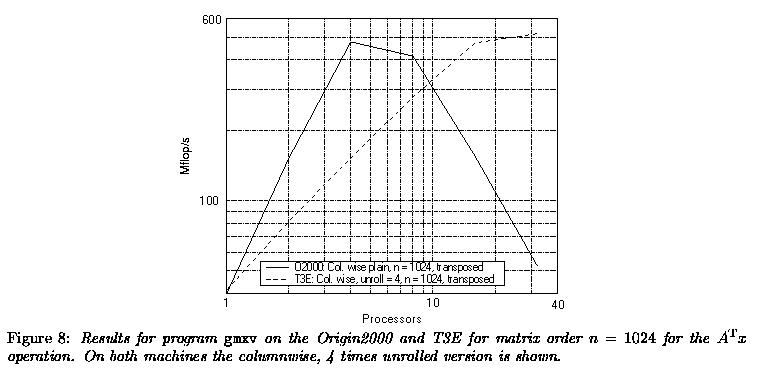
For the transposed matrix-vector multiplication data have to be exchanged between processors as the matrix and the result vector are distributed rowwise over the processors. The amount of communication consists of an all-to-all communication of partial result vectors between the processors: p(p-1) messages of length n/p are sent around. In Figure 8 the results for the fastest implementations are displayed.
The behaviour of the algorithm on the Origin2000 is not very good. The communication is taking already as much as 81% of total execution time on 8 processors. This is apparent in the decreased Mflop-rate from 8 processors on. The problem lies in a less than optimal MPI implementation which does a fair amount of buffer copying that is not strictly necessary. Silicon Graphics is presently working on the problem. On the T3E the communication time is growing as expected. The total amount of bytes to be communicated is n(p-1). In addition, the number of messages grows with O(p2) while the message length decreases as O(1/p). The net result is that on two processors 18% of the time is spent in communication, while on 32 processors this fraction has increased to 62%. This is clearly observable in Figure 8. Above 64 processors no speedup can be expected.
3.2.3 Results of mod2f
Program mod2f performs a 1-D FFT of various sizes. As a radix-4 algorithm
is employed, only transform lengths that are powers of 2 are
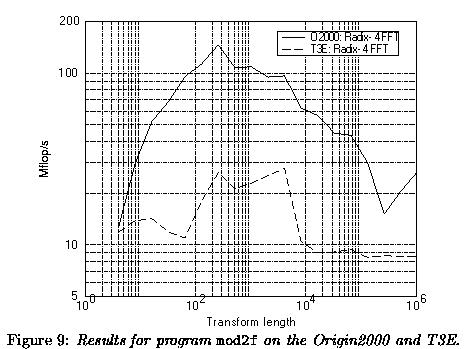
considered. In Figure 9 the results of the single processor versions
on the Origin2000 and the T3E are given.
The performance as a function of the transform length n is rather capricious
on both systems. The access/storage pattern of operands is
fairly complicated. They either are read or written with strides that
are a power of 2. It is clear that beyond transform a length of 8192
both systems degrade in performance because of cache problems
(three arrays of the transform length are involved in the computation).
Both
have their optimal region between lengths of 256--4096. However,
the performance of the R10000 is significantly higher than that of
the
Alpha 21164 over the whole problem range, being from 3--7 times faster
except for n = 4. For n ? 8192 the speed on the T3E is reduced to
roughly 8 Mflop/s, the same speed as was found for out-of-memory
dyadic operations. This suggests that in this range the speed is completely
determined by the available processor-to-memory bandwidth.
3.2.4 Distributed memory results of mod2f
On both systems we also executed a distributed memory implementation of the FFT program: disfft. The actual implementation is slightly different from that of mod2f. Although the same radix-4 FFT is employed, in disfft, the 1-D FFT is actually executed as a product of small 1-D FFTs arranged in a 2-D array.
The advantages are that the small FFTs fit easier into the cache and that the sequence of small FFTs are completely independent. The disadvantages are that n additional multiplications have to be done and that one global transposition of the 2-D array is required, leading to p(p -1) messages of length n/p (all-to-all) communication). The result for a transform length 65,536 is shown in figure 10 for both systems.
It is clear from Figure 10 that the communication on the Origin2000 is not optimal. This is ascribed to the MPI implementation problems mentioned earlier. The performance drops by more than 10% from 1 to 2 processors. After this initial drop the scaling is more or less linear, up to 16 processors but the performance is always at least 60--70% lower than that from the T3E. The scaling on the T3E is slightly sublinear: the speedup on 2 processors is 1.85 while on 32 processors it is 22.49. This is explained by the increasing amount of communication: the growth is O(p2 ) (although the message length decreases with O(1/p)). The communication takes 17.6% of the total execution time on 2 processors while this percentage has grown to 38.4% on 32 processors. By contrast, the communication times on the Origin2000 are highly erratic. On 2 processors is is about 50 %, on 8 processors it is as much as 84%, while on 32 processors it is 52% again. It is clear that with such communication behaviour no conclusions about the scaling of the algorithm can be drawn for this system.
4 Concluding remarks
In the previous sections we have not discussed all results of the Benchmark. Particularly, the results of pro- grams from module 3 are not shown. The analysis of these programs and there relation to the performances of the lower modules would warrant a paper in its own right. For those who are interested in the full results to do their own analysis the results are available via:
http://www.fys.ruu.nl/ ~ steen/euroben/results/.
One should be careful however, because the experiments are not completely finished and updates may occur in the near future.
The experiments so far have shown us that as a single-processor system the Origin2000 is generally faster than the T3E, often by a factor of 2 or more, notwithstanding the higher clock speed of the T3E processor. We surmise that this is not only an effect of a lower processor-cache and processor-memory bandwidth but also because of better utilisation of the Origin2000 processor.
The results sofar suggest that one has to pay a performance penalty for using the Origin2000 as a shared- memory system. The overhead involved in cache coherency, synchronisation and the non-uniform access time for physically distributed data result in a lower speedup than that for a corresponding distributed memory code.
Although the lower communication latency of the Origin2000 would suggest otherwise, in practical situation the communication on the T3E is more efficient. The present MPI implementation on the Origin2000 is presently not optimal while it is very good on the T3E.
A further analysis of the Origin2000 results is required to assess the influence of the the secondary cache and the possible influence of data placement and process migration in the shared-memory parallel programming model.
Acknowledgements
I would like to thank Silicon Graphics for providing access to their central testing facilities in Cortaillod, Switzerland and in particular Ruud van der Pas of Silicon Graphics' European HPC Team for helping me with the experiments on the Origin2000. Also I thank the HPaC Centre at the Delft University of Technology for the use of their T3E system.
REFERENCES
[1] D. Fraser, Algorithm 545, An optimized mass storage FFT, in CACM,
Vol. III, ACM, New York, 1983.
[2] A. Friedli, W. Gentzsch, R.W. Hockney, A.J. van der Steen, A European
supercomputer benchmark effort, Supercomputer 6, 6, (1989) 14--17.
[3] R.W. Hockney, A framework for benchmark performance analysis, Supercomputer,
9, 2, (1992) 9--22.
[4] R.W. Hockney, f 1=2 : A parameter to characterize memory and communication
bottlenecks, Parallel Computing, 10 (1989) 277-286.
[5] R.W. Hockney, M. Berry, Public International Benchmarks for Parallel
Computers, Parkbench Committee, Report-1, Febr. 1994 (available through
www.netlib.org/parkbench)
[6] R.W. Hockney, C.R. Jesshope, Parallel Computers 2, Adam Hilger
Ltd, Bristol, 1988.
[7] N. Itoh, Y. Kanada, Monte Carlo Simulation of the Ising model and
random number generation on vector processors, in: Proceedings of Supercomputing
'90, IEEE Computer Society, 1990, 753--762.
[8] Knuth, D.E., The Art of Computer Programming 2, Semi-numerical
algorithms, Addison-Wesley, New York, 1981.
[9] Silicon Graphics Inc., Origin Servers, Technical Report, April
1997.
[10] A.J. van der Steen, Is it really possible to benchmark a supercomputer?
A graded approach to performance measurement, in Evaluating Supercomputers,
UNICOM Proceedings, London, Ed.: A.J. van der Steen, Chapman & Hall,
London, 1990.
[11] A.J. van der Steen, Portable parallel generation of random numbers,
Supercomputer, 7, 1, (1990) 18--20.
[12] A.J. van der Steen, The benchmark of the EuroBen Group, Parallel
Computing, 17, (1991) 1211-1221.
[13] A.J. van der Steen, Overview of recent supercomputers, 7th Edition,
NCF, The Hague, 1997.