Performance Comparison of MPI, PGHPF/CRAFTand HPF
Implementations of the Cholesky Factorisation on the Cray T3E-600 and IBM
SP-2
Iowa State University
Ames, Iowa 50011-2251, USA
January 1998
ABSTRACT
This paper compares the parallel
performance of MPI, PGHPF/CRAFT and HPF implementations of the Cholesky
factorization on the Cray T3E-600 and IBM SP-2 (PGHPF/CRAFT is not available
on the SP-2). These tests were designed to evaluate the performance of
the Cholesky factorization with and without explicit message passing. The
MPI implementation significantly outperformed all other implementations.
The added flexibility of the PGHPF/CRAFT language/compiler over HPF allows
one to implement the Cholesky factorization in a manner that provides about
two to six times the performance of the fastest HPF implementation on the
Cray T3E-600.
1. INTRODUCTION
This paper compares the parallel performance of Message Passing Interface
(MPI) [9], PGHPF/CRAFT [8] and High Performance Fortran (HPF) [1] implementations
of the Cholesky factorization [2] on the Cray T3E-600 and IBM SP-2. The
goal of this paper is to assess the performance of the Cholesky factorization
written in two different parallel languages without explicit message passing
and then compare their performance with the performance of a version with
explicit message passing using MPI. PGHPF/CRAFT includes most of HPF plus
some additional parallel language constructs that provide the programmer
more control over a program's execution. Thus, we also want to find out
how these additional language features will affect the performance of the
Cholesky factorization. The MPI and HPF implementations were run on both
the Cray T3E-600 and IBM SP-2. The PGHPF/CRAFT implementation was only
run on the Cray T3E-600 since this compiler is not available on the SP-2.
The Cray T3E-600 used is located at Cray Research's corporate headquarters
in Eagan, Minnesota. The peak theoretical performance of each processor
is 600 Mflop/s. The communication network has a bandwidth of 350 MB/second
and latency of 1.5 microsecond. The operating system used is UNICOS/mk
version 1.3.1. The Fortran compiler used was cf90 version 3.0 with the
"-O2" option and the PGHPF/CRAFT compiler used was pghpf version 2.3 with
the "-Mcraft -O2" option. All floating point arithmetic was done using
the default "real" precision, i.e., 8 byte words.
The IBM SP-2 used is located at the Maui High Performance Computing
Center, Maui, Hawaii. The peak theoretical performance of each processor
is 267 Mflop/s. The communication network has a peak bandwidth of 40MB/second
with a latency of 40.0 microseconds. Thin nodes have a 64 KB data cache,
64 bit path from the memory to the data cache, and 128 bit path from the
data cache to the processor bus. The operating system used was AIX version
4.1. The Fortran compiler used was mpxlf version 3.2.5 with the "-O2" option
and the HPF compiler used was xlhpf version 1.1 with the "-O2" option.
All results were run submitting the programs to a 16 thin node loadleveler
queue. All floating point arithmetic was done using IBM's "double precision",
i.e., 8 byte words.
2. BASIC SERIAL CHOLESKY FACTORIZATION ALGORITHM
Let A be a real, symmetric, n n matrix. Let A=LLT
be the Cholesky factorization of A, where L is a lower triangular
matrix. The unblocked, serial Cholesky factorization algorithm can be written
as:
do j=1, n
A(j,j) = sqrt(A(j,j))
A(j+1:n,j) = A(j+1:n,j) / A(j,j)
A(j+1:n,j+1) = A(j+1:n,j+1) - {use *GEMV to update
A(j+1:n,1:j)AT(j+1,1:j) A(j+1:n,j+1)}
enddo
where the lower triangular portion of A is L upon completion
of the above loop. As in [2], call this algorithm DLLT. Notice that DLLT
has been optimized by calling the level 2 BLAS routine, *GEMV [5].
Better serial performance can be obtained on machines with data caches
by using a blocked algorithm and level 3 BLAS [3] routines. Partition A
into column blocks each with lb columns of A. For simplicity
of exposition, assume lb divides n. A column blocked Cholesky
factorization algorithm [7] can be written as follows, where the values
of L are stored in the lower triangular portion of A:
do j=1, n / lb
m = ( j - 1) * lb + 1
m1 = m + lb
k = m + lb - 1
k1 = m1 + lb - 1
A(m:k,m:k) = L(m:k,m:k)LT(m:k,m:k)
{use DLLT to solve
for L(m:k,m:k)}
A(m1:n,m:k) = L(m1:n,,m:k)LT(m:k,m:k)
{use *TRSM to solve for L(m1:n,m:k)}
A(m1:n,m1:n) = A(m1:n,m1:n)
{use *SYRK to update L(m1:n,m:k)LT(m1:n,m:k) A(m1:n,m1:n)}
enddo
Table 1 shows the performance of the serial blocked algorithm
in Mflop/s on the Cray T3E-600 and the IBM SP-2. The drop in performance
for n = 2048 on T3E-600 appears to be a performance bug in one of the BLAS
routines and has been reported to Cray.
|
Machine
|
n = 512
|
n = 1024
|
n = 2048
|
|
Cray T3E-600
|
216
|
230
|
125
|
|
IBM SP-2
|
162
|
180
|
180
|
Table 1 : Serial blocked Cholesky in Mflops/s
3. A PARALLEL CHOLESKY FACTORIZATION ALGORITHM WITH MPI
In this section, a parallel Cholesky factorization algorithm for distributed
memory parallel computers is presented with explicit message passing. Since
MPI is rapidly becoming the standard for writing message passing codes
and is available on the machines used in this paper, MPI was used to implement
this algorithm. This algorithm is based on parallelizing the *SYRK portion
of the serial column blocked Cholesky factorization algorithm described
in the previous section.
Data distribution among processors is critical for achieving good performance.
There are many ways of distributing the array A across multiple
processors. Our experiments show that row/column blocked cyclic
data distributions of A provide better load balancing and performance
over row/column blocked data distributions, (see [1]). Moreover,
our experiments show that column-blocked cyclic data distributions
provide better performance than row-blocked cyclic data distributions.
The parallel Cholesky factorization in SCALAPACK uses the blocked cyclic
data distribution for A in both dimensions and provides good performance
and scalability, (see [4,6]). However, it is significantly easier to program
the Cholesky factorization with MPI, HPF and CRAFT using a column blocked
cyclic distribution of A rather than a blocked cyclic distribution
in both dimensions. Thus the column-blocked cyclic data distribution of
A was used to illustrate the performance differences between the
MPI, PGHPF/CRAFT and the HPF implementations. Assume A has been
distributed this way.
The parallel algorithm can be described using the same notation and
the same three main steps for each j in the serial column blocked
algorithm in the previous section:
Step 1: The processor containing the block A(m:k,m:k)
applies the serial DLLT to solve for L(m:k,m:k) in
A(m:k,m:k) = L(m:k,m:k)LT(m:k,m:k)
Step 2: Solve for L(m1:n,m:k), the rectangular portion
of A below A(m:k,m:k), in the following equation:
A(m1:n,m:k) = L(m1:n,m:k)LT(m:k,m:k)
using serial *TRSM. Notice that since A(m:k,m:k) and A(m1:n,m:k)
reside on the same processor, this step is calculated by the processor
in the step 1. After solving for L(m1:n,m:k) the processor broadcasts
L(m1:n,m:k) to the other processors for the calculation in step
3. A barrier is needed at this point since all processors need the values
of L(m1:n,m:k) to execute step 3.
Step 3: Update A(m1:n,m1:n), the square portion of A
to the right of A(m1:n,m:k), by A(m1:n,m1:n) = A(m1:n,m1:n) -
L(m1:n,m:k)LT(m1:n,m:k)
This calculation is done in parallel using serial *GEMM and serial *SYRK,
since each processor has its portion of A(m1:n,m1:n) and each processor
has a copy of L(m1:n,m:k) from the broad cast in step 2. Note that
both *SYRK and *GEMM must be used (instead of only using *SYRK), because
the portions of A(m1:n,m1:n) that reside on each processor are not
symmetric square submatrices. Note also that no barrier is needed here.
No barrier is set in the MPI implementation, since the current mpi_bcast
subroutine has an implicit barrier on the Cray T3E-600 and IBM SP-2. See
appendix A for the MPI implementation of this algorithm and Table 2 and
3 for the results in Mflop/s on the Cray T3E-600 and IBM SP-2 respectively.
Figures 1-3 show the performance comparison on the IBM SP-2 and T3E-600.
For each problem size and for each number of processors, block sizes of
4, 8, 16, and 32 were tested and the best performance numbers are reported.
We found that the block size giving optimal performance depended on both
the problem size and the number of processors used. Again notice the drop
in performance on the Cray T3E-600 when n=2048. Figure 1 illustrates
this data when n=1024.
|
# of processors
|
n = 512
|
n = 1024
|
n = 2048
|
|
2
|
300
|
364
|
176
|
|
4
|
402
|
557
|
327
|
|
8
|
504
|
753
|
587
|
|
16
|
585
|
956
|
967
|
Table 2 : The MPI Cholesky on the T3E-600 in Mflops/s
|
# of processors
|
n = 512
|
n = 1024
|
n = 2048
|
|
2
|
186
|
278
|
342
|
|
4
|
186
|
302
|
497
|
|
8
|
168
|
388
|
553
|
|
16
|
310
|
489
|
804
|
Table 3 : The MPI Cholesky on the SP-2 in Mflops/s
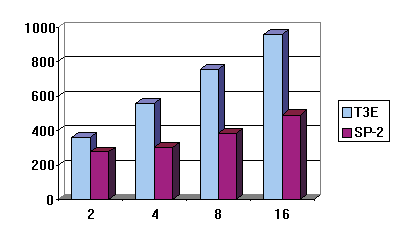 Figure 1: The MPI Cholesky in Mflop/s when n=1024.
Figure 1: The MPI Cholesky in Mflop/s when n=1024.
4. THE PGHPF/CRAFT IMPLEMENTATION
The PGHPF/CRAFT compiler from the Portland Group is available for the Cray
T3E-600 and supports the HPF language and Cray's CRAFT programming language
(see [8]). HPF and CRAFT are high level languages that allow one to write
parallel programs without explicit message passing. CRAFT provides the
programmer more control of the execution of the parallel program than the
current version of HPF. In this section, a PGHPF/CRAFT implementation of
the serial column blocked Cholesky factorization algorithm is presented
using the column-blocked cyclic data distribution of the array A.
To distinguish this implementation from the HPF implementation, we shall
call this the "CRAFT" implementation.
We used the following features of CRAFT that are not available in HPF:
-
The intrinsic function my_pe() returns the id of the executing processor.
This is needed to control the calculation based on the executing processor.
-
The shared to private conversion of data via CRAFT subroutines allows one
to call serial BLAS routines for calculations on local portions of shared
arrays, i.e. arrays distributed across the processors.
HPF does provides EXTRINSIC(HPF_LOCAL) capability for procedures. However
this can not be used to call serial BLAS routines since HPF does not allow
for private data and since there is no way to control program execution
based on the executing processor.
The CRAFT implementation can be described using the same notation and
the same three steps from the previous section:
Step 1: The processor containing the block A(m:k,m:k)
applies the serial DLLT to solve for L(m:k,m:k) in A(m:k,m:k)
= L(m:k,m:k)LT(m:k,m:k)
This can be done by using the intrinsic function my_pe() in an IF structure.
Step 2: Solve for L(m1:n,m:k) in the equation:
A(m1:n,m:k) = L(m1:n,m:k)LT(m:k,m:k)
using serial *TRSM. Since A(m:k,m:k) and A(m1:n,m:k)
reside on the same processor, this step is calculated by the processor
in the step 1. A barrier is needed after the subroutine call, using
!hpf$ barrier, to ensure that the L(m1:n,m:k) is solved before proceeding
to the next step. The values of L(m1:n,m:k) are then broadcast to
all the processors by writing:
T(m1:n,1:lb)=L(m1:n,m:k)
where T is a two dimensional private array.
Step 3: Update A(m1:n,m1:n) by A(m1:n,m1:n) = A(m1:n,m1:n)
- L(m1:n,m:k)LT(m1:n,m:k)
This is done in parallel by passing A into a subroutine and
using the shared to private mechanism. Each processor then performs the
calculation on the local data of A using the values of T
from step 2 and using serial *SYRK and serial *GEMM. No barrier is needed
at this step.
Notice that this CRAFT implementation is able to logically follow the MPI
implementation but is significantly easier to program because there is
no explicit message passing. See appendix B for the CRAFT implementation
code and Table 4 for the results in Mflop/s on the Cray T3E-600. All data
distributions of A were tried and the one giving the best performance
was A(*, cyclic(size)). The optimal block size was 32. Notice that
(excluding n=2048 where there is an apparent bug in the performance
of SGEMM) the MPI implementation varies from 2 to 4 times faster than the
CRAFT implementation.
|
# of processors
|
n = 512
|
n = 1024
|
n = 2048
|
|
2
|
120
|
173
|
110
|
|
4
|
137
|
216
|
180
|
|
8
|
151
|
252
|
266
|
|
16
|
151
|
268
|
345
|
Table 4 : The CRAFT Cholesky on the T3E-600 in Mflop/s.
5. THE HPF IMPLEMENTATION
To achieve good performance, the MPI and CRAFT implementations require
each executing processor to call serial BLAS routines to perform calculations
on local data of A. This can not be done with the current version
of HPF. Thus the parallelization of the unblocked Cholesky factorization
can only be obtained using the independent and forall directives as follows:
!hpf$ distribute A(cyclic,*)
do j=1,n
A(j,j)=sqrt(A(j,j))
!hpf$ independent
forall(k=j+1:n) A(k,j)=A(k,j)/A(j,j)
if (j.lt.n) then
temp1(1:j)=A(j,1:j)
!hpf$ independent
do i=1,j
A(j+1:n,j+1)=A(j+1:n,j+1)- A(j+1:n,i)*temp1(i)
enddo
endif
enddo
The temporary array temp1 used above is a private (i.e., non-distributed)
one-dimensional array. The use of temp1 gave over 40% increase in performance
on both machines. See appendix C for a complete program listing.
All possible data distributions of A were tried, and the row
cyclic data distribution, A(cyclic,*), provided the best performance. Tables
5 and 6 show the results in Mflop/s on the Cray T3E-600 and IBM SP-2 respectively
and figures 2 and 3 compare the performance of the different implementations
for n=1024.
|
# of processors
|
n = 512
|
n = 1024
|
n = 2048
|
|
2
|
27
|
28
|
28
|
|
4
|
48
|
54
|
56
|
|
8
|
72
|
94
|
107
|
|
16
|
83
|
134
|
179
|
Table 5 : The HPF Cholesky on the T3E-600 in Mflop/s
|
# of processors
|
n = 512
|
n = 1024
|
n = 2048
|
|
2
|
51
|
57
|
62
|
|
4
|
48
|
78
|
106
|
|
8
|
58
|
102
|
152
|
|
16
|
62
|
115
|
180
|
Table 6 : The HPF Cholesky on the SP-2 in Mflop/s
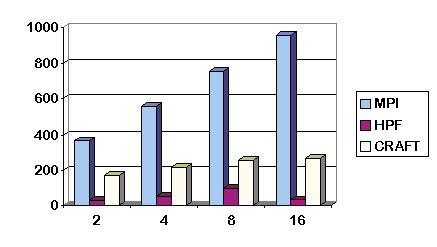 Figure 2: The MPI, HPF & CRAFT implementations on the T3E for
n=1024.
Figure 2: The MPI, HPF & CRAFT implementations on the T3E for
n=1024.
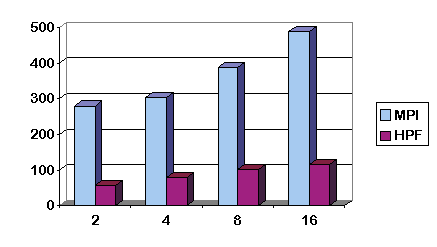 Figure 3: The MPI & HPF implementations on the SP-2 for n=1024.
Figure 3: The MPI & HPF implementations on the SP-2 for n=1024.
Notice that on the Cray T3E-600, the CRAFT implementation ranges from
1.8 to 6.2 times faster than the HPF implementation and the MPI implementation
ranges from 5.4 to 13 times faster than the HPF implementation. Notice
also that on the IBM SP-2 the MPI implementation ranges from 2.9 to 5.5
times faster than the HPF implementation.
The blocked Cholesky factorization algorithm was also implemented using
HPF with the calls to TRSM and SYRK replaced with HPF code, see appendix
D. This gave poorer performance than the above HPF implementation.
The serial unblocked Cholesky factorization algorithm was also implemented
using the intrinsic function matmul to perform the *SGEMV operations. The
performance of this implementation turned out to be even worse than the
blocked HPF implementation.
6. CONCLUSIONS
For both the Cray T3E-600 and IBM SP-2, the MPI implementation of the Cholesky
factorization provided significantly better performance than the HPF implementation.
Both HPF and PGHPF/CRAFT allow one to write programs without explicit message
passing. However, PGHPF/CRAFT implementation provides about two to six
times the performance of the fastest HPF implementation on the Cray T3E-600.
This increased performance is because the PGHPF/CRAFT implementation allows
one to (1) logically follow the MPI implementation and (2) call optimized
BLAS routines.
The PGHPF/CRAFT implementation can call serial optimized BLAS routines
since PGHPF/CRAFT language/compiler allows private data and program execution
control based on the executing processor via the my_pe() intrinsic function.
HPF does not currently have this capability.
Note that, because of the above, the PGHPF/CRAFT implementation of the
Cholesky factorization has the potential of performing as well as the MPI
implementation.
We therefore recommend that the following capabilities be considered
for inclusion in future versions of the HPF language:
-
The ability to know what processor ones code is executing on via something
like the my_pe() intrinsic function.
-
Allow private data and the automatic shared-to-private conversion via procedures
as is done in CRAFT.
Appendices
ACKNOWLEDGMENTS
Computer time on the Maui High Performance Computer Center's SP-2 was sponsored
by the Phillips Laboratory. Air Force Material Command, USAF, under cooperative
agreement number F29601-93-2-0001. The views and conclusions contained
in this document are those of the authors and should not be interpreted
as necessarily representing the official policies or endorsements, either
expressed or implied, of Phillips Laboratory or the U.S. Government.
We would like to thank Cray Research Inc. for allowing us to use their
Cray T3E at their corporate headquarters in Eagan, Minnesota, USA.
REFERENCES
[1] High Performance Fortran Languages Specification, Version 2.0,
Rice University, Houston, Texas, October 19,1996
[2] Golub, G.H., and Van Loan, C.F. Matrix Computations. Johns
Hopkins Univ. press, Baltimore, Md, 1989.
[3] Glenn R. Luecke, Jae Heon Yun, and Philip W. Smith, Performance
of Parallel Cholesky Factorization Algorithms Using BLAS. The
Journal of Supercomputing, 6 pp. 315-329, 1992.
[4] Glenn R. Luecke, James J. Coyle, High Performance Fortran versus
explicit message passing on the IBM SP-2for the parallel LU, QR,
and Cholesky factorizations. Supercomputer Volume XIII number 2, 1997.
[5] J. Dongarra, J. Du Croz, I. Duff, S. Hammarlin, Algorithm 679:
A set of Level 3 Basic Linear Algebra Subprograms, ACM Trans.
Math. Soft., vol. 16, pp. 18-28, 1990
[6] Jack J. Dongarra, Jaeyoung Choi, L. Susan, Antoine P. Petitet,
David W. Walker, R. Clint Whaley The design and implementation of the
scalapack LU QR and Cholesky factorization routines. ORNL/TM-12470,
September, 1994.
[7] Mayes, P., and Radicati di Brozolo, G. Portable and efficient
factorization algorithms on the IBM 3090/VF. Inc. proc., 1989
Internat. Conf. on Supercomputing, ACM Press, pp. 263-270, 1989.
[8] URL : http//www.cray.com/products/software/pe/hpf.html
[9] W. Gropp, E. Lusk, A. Skjellum, Using MPI, The MIT Press,
1994.