




The technological driving force behind parallel computing is VLSI, or very large scale integration-the same technology that created the personal computer and workstation market over the last decade. In 1980, the Intel 8086 used 50,000 transistors; in 1992, the latest Digital alpha RISC chip contains 1,680,000 transistors-a factor of 30 increase. The dramatic improvement in chip density comes together with an increase in clock speed and improved design so that the alpha performs better by a factor of over one thousand on scientific problems than the 8086-8087 chip pair of the early 1980s.
The increasing density of transistors on a chip follows directly from a
decreasing feature size which is now 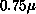 for the alpha. Feature
size will continue to decrease and by the year 2000, chips with
50 million transistors are expected to be available. What can we do
with all these transistors?
for the alpha. Feature
size will continue to decrease and by the year 2000, chips with
50 million transistors are expected to be available. What can we do
with all these transistors?
With around a million transistors on a chip, designers were able to move
full mainframe functionality to about  of a chip. This
enabled the personal computing and workstation revolutions. The next
factors of ten increase in transistor density must go into some form of
parallelism by replicating several CPUs on a single chip.
of a chip. This
enabled the personal computing and workstation revolutions. The next
factors of ten increase in transistor density must go into some form of
parallelism by replicating several CPUs on a single chip.
By the year 2000, parallelism is thus inevitable to all computers, from your children's video game to personal computers, workstations, and supercomputers. Today we see it in the larger machines as we replicate many chips and printed circuit boards to build systems as arrays of nodes, each unit of which is some variant of the microprocessor. This is illustrated in Figure 1.1 (Color Plate), which shows an nCUBE parallel supercomputer with 64 identical nodes on each board-each node is a single-chip CPU with additional memory chips. To be useful, these nodes must be linked in some way and this is still a matter of much research and experimentation. Further, we can argue as to the most appropriate node to replicate; is it a ``small'' node as in the nCUBE of Figure 1.1 (Color Plate), or more powerful ``fat'' nodes such as those offered in CM-5 and Intel Touchstone shown in Figures 1.2 and 1.3 (Color Plates) where each node is a sophisticated multichip printed circuit board? However, these details should not obscure the basic point: Parallelism allows one to build the world's fastest and most cost-effective supercomputers.

Figure 1.1 : The nCUBE-2 node and its integration into
a board. Upto 128 of these boards can be combined into a single
supercomputer.

Figure 1.2 : The CM-5 produced by Thinking Machines.

Figure 1.3 : The DELTA Touchstone parallel
supercomputer produced by Intel and installed at Caltech.
Parallelism may only be critical today for supercomputer vendors and users. By the year 2000, all computers will have to address the hardware, algorithmic, and software issues implied by parallelism. The reward will be amazing performance and the opening up of new fields; the price will be a major rethinking and reimplementation of software, algorithms, and applications.
This vision and its consequent issues are now well understood and
generally agreed. They provided the motivation in 1981 when
C P's first roots were formed. In those days, the vision was blurred
and controversial. Many believed that parallel computing would not
work.
P's first roots were formed. In those days, the vision was blurred
and controversial. Many believed that parallel computing would not
work.
President Bush instituted, in 1992, the five-year federal High Performance Computing and Communications (HPCC) Program. This will spur the development of the technology described above and is focussed on the solution of grand challenges shown in Figure 1.4 (Color Plate). These are fundamental problems in science and engineering, with broad economic and scientific impact, whose solution could be advanced by applying high-performance computing techniques and resources.
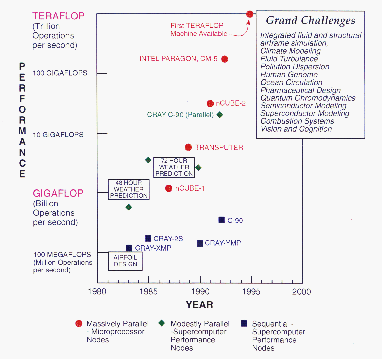
Figure 1.4: Grand Challenge Appications. Some major
applications which will be enabled by parallel supercomputers. The computer
performance numbers are given in more detail in color figure 2.1.
The activities of several federal agencies have been coordinated in this program. The Advanced Research Projects Agency (ARPA) is developing the basic technologies which is applied to the grand challenges by the Department of Energy (DOE), the National Aeronautics and Space Agency (NASA), the National Science Foundation (NSF), the National Institute of Health (NIH), the Environmental Protection Agency (EPA), and the National Oceanographic and Atmospheric Agency (NOAA). Selected activities include the mapping of the human genome in DOE, climate modelling in DOE and NOAA, coupled structural and airflow simulations of advanced powered lift and a high-speed civil transport by NASA.
More generally, it is clear that parallel computing can only realize its full potential and be commercially successful if it is accepted in the real world of industry and government applications. The clear U.S. leadership over Europe and Japan in high-performance computing offers the rest of the U.S. industry the opportunity of gaining global competitive advantage.
Some of these industrial opportunities are discussed in Chapter 19. Here we note some interesting possibilities which include
C P did not address such large-scale problems. Rather, we
concentrated on major academic applications. This fit the
experience of the Caltech faculty who led most of the C
P did not address such large-scale problems. Rather, we
concentrated on major academic applications. This fit the
experience of the Caltech faculty who led most of the C P teams, and
further academic applications are smaller and cleaner than large-scale
industrial problems. One important large-scale C
P teams, and
further academic applications are smaller and cleaner than large-scale
industrial problems. One important large-scale C P application was
a military simulation described in Chapter 18 and produced
by Caltech's Jet Propulsion Laboratory. C
P application was
a military simulation described in Chapter 18 and produced
by Caltech's Jet Propulsion Laboratory. C P chose the correct and
only computations on which to cut its parallel computing teeth. In
spite of the focus on different applications, there are many
similarities between the vision and structure of C
P chose the correct and
only computations on which to cut its parallel computing teeth. In
spite of the focus on different applications, there are many
similarities between the vision and structure of C P and today's
national effort. It may even be that today's grand challenge teams can
learn from C
P and today's
national effort. It may even be that today's grand challenge teams can
learn from C P's experience.
P's experience.