What is BFD?
How many times have you seen a message like the following?
ERROR
Requested document (URL http://j.random.host/file.html)
could not be accessed.The information server either is not
accessible or is refusing to serve the document to you.
The motivation behind BFD is to make it so that you will never
(well, hardly ever) see that message!
BFD stands for Bulk File Distribution. It is a system for
transparently mirroring files between cooperating file servers,
and keeping track of where the mirrored copies are.
The locations of the mirrored copies are stored in a distributed
database which is accessible from a BFD-aware WorldWideWeb (W3) browser.
When using such a browser, when you click on a phrase or icon to a
particular web page, the client will consult the BFD location database
to see if knows about any mirrored copies of that page. If so, the
client will access the page from one of the mirrored servers. (If the
first mirrored server is unavailable, it will try the second one, and
so on, until it finds one that works.) If all else fails, the browser
will attempt to fetch the page from the primary server.
But what if the mirrored copy is out-of-date?
BFD is designed to make that unlikely. If the software used to mirror
one file server to another is also BFD-aware, that software will
update the BFD location database every time it copies a new file.
Also, the browser can find out the date at which the mirrored file was
copied from the primary server, and display that to the user.
Finally, for files that are published using BFD, BFD can
provide reasonable assurances (to within seconds) that the file is
current, and also allow the client to check the integrity of the file
(so you will know that the file isn't corrupted).
Won't BFD slow things down?
In some cases, accessing a file via BFD and a mirror server may be
slower than it would have been to access the file from the location in
its URL. However, the really annoying cases are where you have to
wait several seconds only to find out that a file isn't available,
shouldn't happen nearly as often.
What's more, with BFD it is possible to have a popular web page
mirrored on dozens of servers all around the world. The browser can
then decide (using heuristics) which mirror server is the closest to
you, or which one is most likely to be available, and try that one
first. If the browser can fetch a file from a nearby site,
it's almost certainly faster than fetching it from a file halfway
across the planet.
Finally, with BFD, a popular web site can scale dramatically, by
mirroring its files on several machines which share the load.
How does BFD work?
There are several components to BFD, including:
- Name (URN) Servers
- Location (URL) Servers
- Replication Daemons
- Collection Managers
- File Servers
- Clients
- Other tools
Each of these will be described in turn.
In our implementation, the URN server and LIFN server are
pulled together into the
Resource Catalog (RC) Server.
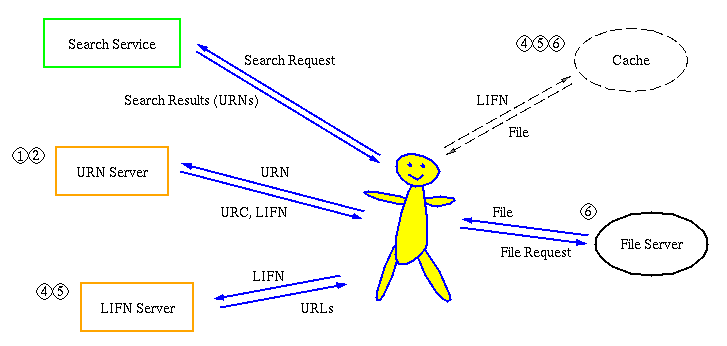
Name (URN) Servers
A name server manages a database of meta-information about
files that are managed by BFD. Each file managed by BFD is assigned a
Uniform Resource Name (URN) which can be used to refer to the
file. Given a URN, a Web browser can query a name server for that URN
and find out some information about that file.
Among the information stored for each file is a
Location-Independent File Name (LIFN). A LIFN is a name for
a specific sequence of bytes that corresponds to the current
version of the file. Other pieces of information about the file which
might be available from the URN server would include the file's
``catalog information'' (title, author, description, etc.,) as well as
``instance information'' such as content-type, size, MD5 fingerprint,
and a cryptographically signed certificate of authenticity.
Name servers can also collect statistics about which URNs are
requested most often, and when, to aid the collection manager in
knowing which files to acquire, which ones to keep on-hand, and which
ones to reap.
Location (URL) Servers
A location server manages a database of LIFN-to-location
(URL) bindings. Every time a file server makes a new file available
via BFD, it informs a location server. If a Web client subsequently
asks for locations for a particular LIFN, the location server will
then respond with a list of URLs where that file can be found.
NOTE: The distinction between a URN and a LIFN is subtle but
important. A URN is a long-lasting name that can be used by humans to
refer to some network-accesible resource: be it a Web page, a telnet
session, or a MUD. However, the exact contents of the resource named
by the URN can change. Accessing a URN for ``today's newspaper''
would give you different results today than yesterday.
The use of LIFNs is more restricted. First of all, a LIFN can only
refer to a file; it cannot be used to name other kinds of network
accessible resources. Second, once a LIFN has been assigned to a
specific sequence of bytes, that LIFN cannot be used to name any other
sequence of bytes. Finally, LIFNs are not really intended to be used
by humans (though this might happen occasionally); they were created
so that the various components of BFD could all have a common,
unambiguous name for every file managed by BFD.
Replication Daemons
A replication daemon performs the task of acquiring new files from
remote servers, deleting files that are no longer wanted, and
informing the location servers of the changes. This function is
similar to that provided by several existing ``mirror'' programs, but
in addition to copying files from one server to another, the
replication daemon also propagtes each file's LIFN and any other
information which is needed by the file server.
The BFD replication daemon is designed to perform its task very
efficiently. Planned features include on-the-wire compression,
checkpoint/restart, multiple file multiplexing (to allow for the
gradual transfer of very large files without pre-empting small ones),
integrity checking, and a protocol which works well over high
bandwidth-delay links.
Collection Managers
A collection manager decides which files to acquire, which ones to
keep, and which ones to throw away. It makes such decisions based on
access statistics (as obtained from the file server or a name server),
and site-specified criteria. The results of such decisions are then
fed to one or more replication daemons. If several file servers are
under control of a single administration, a single collection manager
may make decisions for several of its file servers, and transmit
the instructions to each file server via the network.
File Servers
File servers in BFD are essentially ordinary HTTP, Gopher, or FTP
servers which provide file access to BFD-managed files for Web
browsers.
Clients
BFD clients are slightly modified Web browsers which, in addition to
having the capability to retrieve a file given its URL, also have the
capability to retrieve files (by consulting name and/or location
servers) by URN or LIFN.
Since URNs and LIFNs cannot be expected to be widely used for some
time, a transition strategy has been
developed that provides some of the benefits of BFD for files accessed
by a URL.
Other tools
Other tools will be necessary to implement BFD fully. In particular,
there will be a need for tools to help publishers manage their
collections, tools to help authors and editors maintain the catalog
information for their works, and a mechanism to export various kinds
of meta-information to resource discovery systems such as Harvest.
Use of URNs and LIFNs for publishing and accessing files is
illustrated in Figures 1 and 2.
Figure 1:
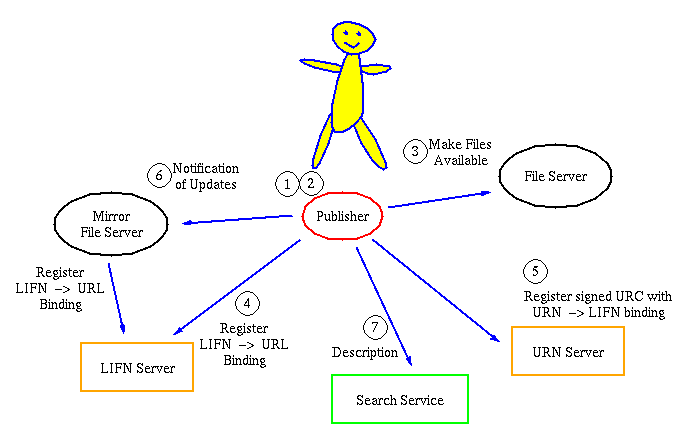
Figure 2: