Statistics




Next: History of PVM
Up: Debugging the System
Previous: Sane Heap
 The pvmd includes several registers and counters to sample certain
events,
such as the number of calls made to select() or
the number of packets refragmented
by the network code.
These values can be computed from a debug log ,
but the counters have less adverse impact on
the performance of the pvmd than would generating a huge log file.
The counters can be dumped or reset using the pvm_tickle()
function or the console tickle command.
The code to gather statistics
is normally switched out at compile time.
To enable it,
one
edits the makefile and adds -DSTATISTICS to the compile options.
The pvmd includes several registers and counters to sample certain
events,
such as the number of calls made to select() or
the number of packets refragmented
by the network code.
These values can be computed from a debug log ,
but the counters have less adverse impact on
the performance of the pvmd than would generating a huge log file.
The counters can be dumped or reset using the pvm_tickle()
function or the console tickle command.
The code to gather statistics
is normally switched out at compile time.
To enable it,
one
edits the makefile and adds -DSTATISTICS to the compile options.
Glossary
- asynchronous
-
Not guaranteed to enforce coincidence in clock
time. In an asynchronous communication operation, the sender and
receiver may or may not both be engaged in the operation at the same
instant in clock time.
- atomic
-
Not interruptible. An atomic operation is one that always
appears to have been executed as a unit.
- bandwidth
-
A measure of the speed of information transfer
typically used to quantify the communication capability of
multicomputer and multiprocessor systems. Bandwidth can express point-to-point
or collective (bus) communications rates. Bandwidths are
usually expressed in megabytes per second.
- barrier synchronization
-
An event in which two or more processes
belonging to some implicit or explicit group block until all members
of the group have blocked. They may then all proceed. No member of
the group may pass a barrier until all processes in the group have
reached it.
- big-endian
-
A binary data format in which the most significant byte or bit comes
first. See also little-endian.
- bisection bandwidth
-
The rate at which communication can take place
between one half of a computer and the other. A low bisection
bandwidth or a large disparity between the maximum and minimum
bisection bandwidths achieved by cutting the computers elements in
different ways is a warning that communications bottlenecks may arise
in some calculations.
- broadcast
-
To send a message to all possible recipients. Broadcast
can be implemented as a repeated send
or in a more efficient method, for example,
over a spanning tree where each node propagates the message to its descendents.
- buffer
-
A temporary storage area in memory. Many methods for
routing messages between processors use buffers at the source and
destination or at intermediate processors.
- bus
-
A single physical communications medium shared by two or more
devices. The network shared by processors in many distributed
computers is a bus, as is the shared data path in many
multiprocessors.
- cache consistency
-
The problem of ensuring that the values
associated with a particular variable in the caches of several
processors are never visibly different.
- channel
-
A point-to-point connection through
which messages can be sent. Programming systems that rely on channels
are sometimes called connection oriented, to distinguish them from
connectionless systems in which messages are sent to
named destinations rather than through named channels.
- circuit
-
A network where connections are established between senders and
receivers,
reserving network resources.
Compare with packet switching.
- combining
-
Joining messages together as they traverse a network.
Combining may be done to reduce the total traffic in the network, to
reduce the number of times the start-up penalty of messaging is
incurred, or to reduce the number of messages reaching a particular
destination.
- communication overhead
-
A measure of the additional workload
incurred in a parallel algorithm as a result of communication between the
nodes of the parallel system.
- computation-to-communication ratio
-
The ratio of the number of
calculations a process does to the total size of the messages it
sends;
alternatively, the ratio
of time spent calculating to time spent communicating,
which depends on the relative speeds of the
processor and communications medium, and on the startup cost and
latency of communication.
- contention
-
Conflict that arises when two or more requests are
made concurrently for a resource that cannot be shared. Processes
running on a single processor may contend for CPU time, or a network
may suffer from contention if several messages attempt to traverse the
same link at the same time.
- context switching
-
Saving the state of one process and replacing
it with that of another. If
little time is required to switch contexts, processor overloading can
be an effective way to hide latency in a message-passing system.
- daemon
-
A special-purpose process that runs on behalf of the system,
for example, the pvmd process or group server task.
- data encoding
-
A binary representation for data objects (e.g., integers, floating-point
numbers) such as XDR or the native format of a microprocessor.
PVM messages can contain data in XDR, native, or foo format.
- data parallelism
-
A model of parallel computing in which a single
operation can be applied to all elements of a data structure
simultaneously. Typically, these data structures are arrays, and the
operations act independently on every array
element or reduction operations.
- deadlock
-
A situation in which each possible activity is blocked,
waiting on some other activity that is also blocked.
- distributed computer
-
A computer made up of smaller and
potentially independent computers, such as a network of workstations.
This architecture is increasingly studied because of its cost
effectiveness and flexibility. Distributed computers are often
heterogeneous.
- distributed memory
-
Memory that is physically distributed among
several modules. A distributed-memory architecture may appear to users
to have a single address space and a single shared memory or may
appear as disjoint memory made up of many separate address spaces.
- DMA
-
Direct memory access, allowing devices on a bus to access
memory without interfering with the CPU.
- efficiency
-
A measure of hardware utilization, equal to the ratio
of speedup achieved on P processors to P itself.
- Ethernet
-
A popular LAN technology invented by Xerox.
Ethernet is a 10-Mbit/S CSMA/CD (Carrier Sense Multiple Access with
Collision Detection) bus.
Computers on an Ethernet send data packets directly to one another.
They listen for the network to become idle before
transmitting,
and retransmit in the event that multiple stations simultaneously
attempt to send.
- FDDI
-
Fiber Distributed Data Interface,
a standard for local area networks
using optical fiber and a 100-Mbit/s data rate.
A token is passed among the stations to control access to send
on the network.
Networks can be arranged in topologies such as stars, trees, and
rings.
Independent counter-rotating rings allow the network to continue
to function in the event that a station or link fails.
- FLOPS
-
Floating-Point Operations per Second, a measure of memory
access performance, equal to the rate at which a machine can perform
single-precision floating-point calculations.
- fork
-
To create another copy of a running process; fork returns twice.
Compare with spawn.
- fragment
-
A contiguous part of a message.
Messages are fragmented so they can be sent over a network having
finite maximum packet length.
- group
-
A set of tasks assigned a common symbolic name,
for addressing purposes.
- granularity
-
The size of operations done by a process between
communications events. A fine-grained process may perform only a few
arithmetic operations between processing one message and the next,
whereas a coarse-grained process may perform millions.
- heterogeneous
-
Containing components of more than one kind. A
heterogeneous architecture may be one in which some components are
processors, and others memories, or it may be one that uses different
types of processor together.
- hierarchical routing
-
Messages are routed in PVM based on a hierarchical address (a TID).
TIDs are divided into host and local parts
to allow efficient local and global routing.
- HiPPI
-
High Performance Parallel Interface, a point-to-point 100-MByte/sec
interface standard used for networking components of high-performance multicomputers together.
- host
-
A computer, especially a self-complete one on a network with others.
Also,
the front-end support machine for, for example, a multiprocessor.
- hoster
-
A special PVM task that performs slave pvmd startup for the master
pvmd.
- interval routing
-
A routing algorithm that assigns an integer
identifier to each possible destination and then labels the outgoing
links of each node with a single contiguous interval or window so that
a message can be routed simply by sending it out the link in whose
interval its destination identifier falls.
- interrupt-driven system
-
A type of message-passing system.
When a message is delivered to its
destination process, it interrupts execution of that process and
initiates execution of an interrupt handler,
which may either process the message or store it
for subsequent retrieval. On completion of the
interrupt handler (which may set some flag or sends some signal
to denote an available message), the original process resumes
execution.
- IP
-
Internet Protocol,
the Internet standard protocol that enables sending datagrams (blocks
of data) between hosts on interconnected networks.
It provides a connectionless, best-effort delivery service.
IP and the ICMP control protocol are the building blocks for
other protocols such as TCP and UDP.
- kernel
-
A program providing basic services on a computer,
such as managing memory, devices, and file systems.
A kernel may provide minimal service
(as on a multiprocessor node)
or many features (as on a Unix machine).
Alternatively,
a kernel may be
a basic computational building-block (such as a fast Fourier transform)
used iteratively or in parallel to perform a larger computation.
- latency
-
The time taken to service a request or deliver a message
that is independent of the size or nature of the operation. The
latency of a message-passing system is the minimum time to deliver any
message.
- Libpvm
-
The core PVM programming library,
allowing a task to interface with the pvmd and other tasks.
- linear speedup
-
The case when a program runs faster in direct proportion to the
number of processors used.
- little-endian
-
A binary data format is which the least significant byte or bit comes
first. See also big-endian.
- load balance
-
The degree to which work is evenly distributed among
available processors. A program executes most quickly when it is
perfectly load balanced, that is, when every processor has a share of
the total amount of work to perform so that all processors complete
their assigned tasks at the same time. One measure of load imbalance
is the ratio of the difference between the finishing times of the
first and last processors to complete their portion of the calculation
to the time taken by the last processor.
- locality
-
The degree to which computations done by a processor
depend only on data held in memory that is close to that
processor.
Also,
the degree to which computations done on part of a
data structure depend only on neighboring values.
Locality can be
measured by the ratio of local to nonlocal data accesses, or by the
distribution of distances of, or times taken by, nonlocal accesses.
- lock
-
A device or algorithm the use of which guarantees some type of exclusive access
to a shared resource.
- loose synchronization
-
The situation when
the nodes on a computer
are constrained to intermittently synchronize with each other via some
communication. Frequently, some global computational parameter such as
a time or iteration count provides a natural synchronization
reference. This parameter divides the running program into compute and
communication cycles.
- mapping
-
An allocation of processes to processors; allocating work
to processes is usually called scheduling.
- memory protection
-
Any system that prevents one process from
accessing a region of memory being used by another. Memory protection
is supported in most serial computers by the hardware and the operating system
and in most parallel computers
by the hardware kernel and service kernel of the
processors.
- mesh
-
A topology in which nodes form a regular acyclic
d-dimensional grid, and each edge is parallel to a grid axis and joins
two nodes that are adjacent along that axis. The architecture of many
multicomputers is a two- or three-dimensional mesh; meshes are also the
basis of many scientific calculations, in which each node represents a
point in space, and the edges define the neighbors of a node.
- message ID
-
An integer handle used to reference a message buffer in libpvm.
- message passing
-
A style of interprocess communication in which
processes send discrete messages to one another. Some computer
architectures are called message-passing architectures because they
support this model in hardware, although message passing has often
been used to construct operating systems and network software for
uniprocessors and distributed computers.
- message tag
-
An integer code (chosen by the programmer) bound to a message as it is sent.
Messages can be accepted by tag value and/or source address
at the destination.
- message typing
-
The association of information with a message that
identifies the nature of its contents. Most message-passing systems
automatically transfer information about a message's sender to its
receiver. Many also require the sender to specify a type for the
message, and let the receiver select which types of messages it is
willing to receive.
See message tag.
- MIMD
-
Multiple-Instruction Multiple-Data,
a category of Flynn's
taxonomy in which many instruction streams are concurrently applied to
multiple data sets. A MIMD architecture is one in which heterogeneous
processes may execute at different rates.
- multicast
-
To send a message to many, but not necessarily all
possible recipient processes.
- multicomputer
-
A computer in which processors can execute separate
instruction streams, can have their own private memories, and cannot
directly access one another's memories. Most multicomputers are
disjoint memory machines, constructed by joining nodes (each
containing a microprocessor and some memory) via links.
- multiprocessor
-
A computer in which processors can execute separate
instruction streams, but have access to a single address space. Most
multiprocessors are shared-memory machines, constructed by connecting
several processors to one or more memory banks through a bus or
switch.
- multiprocessor host
-
The front-end support machine of, for example, a multicomputer.
It may serve to boot the multicomputer,
provide network access,
file service, etc.
Utilities such as compilers may run only on the front-end machine.
- multitasking
-
Executing many processes on a single processor. This
is usually done by time-slicing the execution of individual processes
and performing a context switch each time a process is swapped in or
out, but is supported by special-purpose hardware in some computers.
Most operating systems support multitasking, but it can be costly if
the need to switch large caches or execution pipelines makes context
switching expensive in time.
- mutual exclusion
-
A situation in which at most one process can be
engaged in a specified activity at any time. Semaphores are often used
to implement this.
- network
-
A physical communication medium. A network may consist of
one or more buses, a switch, or the links joining processors in a
multicomputer.
- network byte order
-
The Internet standard byte order (big-endian).
- node
-
Basic compute building block of a multicomputer. Typically a node refers to a
processor with a memory system and a mechanism for communicating with
other processors in the system.
- non-blocking
-
An operation that does not block the execution of
the process using it. The term is usually applied to communications operations,
where it implies that the communicating process may perform other
operations before the communication has completed.
- notify
-
A message generated by PVM on a specified event.
A task may request to be notified when another task exits
or the virtual machine configuration changes.
- NUMA
-
Non-Uniform Memory Access,
an architecture that does
not support constant-time
read and write operations. In most NUMA systems, memory is
organized hierarchically, so that some portions can be read and
written more quickly than others by a given processor.
- packet
-
A quantity of data sent over the network.
- packet switching
-
A network in which limited-length packets are routed independently
from source to destination.
Network resources are not reserved.
Compare with circuit.
- parallel computer
-
A computer system made up of many identifiable
processing units working together in parallel. The term is often used
synonymously with concurrent computer to include both multiprocessor
and multicomputer. The term concurrent is more commonly used in
the United States, whereas the term parallel is more common in Europe.
- parallel slackness
-
Hiding the latency of communication by giving
each processor many different tasks, and having the processors work on the tasks
that are ready while other tasks are blocked (waiting on communication
or other operations).
- PID
-
Process Identifier (in UNIX) that is native to a machine or
operating system.
- polling
-
An alternative to interrupting in a communication system.
A node inspects its communication hardware (typically a flag bit) to see
whether information has arrived or departed.
- private memory
-
Memory that appears to the user to be divided
between many address spaces, each of which can be accessed by only one
process. Most operating systems rely on some memory protection
mechanism to prevent one process from accessing the private memory of
another; in disjoint-memory machines, the problem is usually finding a
way to emulate shared memory using a set of private memories.
- process
-
An address space, I/O state, and one or more threads of program control.
- process creation
-
The act of forking or spawning a new process. If
a system permits only static process creation, then all processes are
created at the same logical time, and no process may interact with any
other until all have been created. If a system permits dynamic
process creation, then one process can create another at any time.
Most first and second generation multicomputers only supported static
process creation, while most multiprocessors, and most operating
systems on uniprocessors, support dynamic process creation.
- process group
-
A set of processes that can be treated as a single
entity for some purposes, such as synchronization and broadcast or
multicast operations. In some parallel programming systems there is
only one process group, which implicitly contains all processes; in
others, programmers can assign processes to groups statically when
configuring their program, or dynamically by having processes create,
join and leave groups during execution.
- process migration
-
Changing the processor responsible for
executing a process during the lifetime of that process. Process
migration is sometimes used to dynamically load balance a program or
system.
- pvmd
-
PVM daemon,
a process that serves as a message router and virtual machine coordinator.
One PVD daemon runs on each host of a virtual machine.
- race condition
-
A situation in which the result of operations
being executed by two or more processes depends on the order in which
those processes execute, for example, if two processes
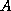 and
and 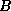 are to
write different values
are to
write different values 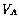 and
and 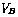 to the same variable.
to the same variable.
- randomized routing
-
A routing technique in which each message is
sent to a randomly chosen node, which then forwards it to its
final destination. Theory and practice show that this can greatly
reduce the amount of contention for access to links in a
multicomputer.
- resource manager
-
A special task that manages other tasks and the virtual machine configuration.
It intercepts requests to create/destroy tasks and add/delete hosts.
- route
-
The act of moving a message from its source to its
destination. A routing algorithm is a rule for deciding, at any
intermediate node, where to send a message next; a routing technique
is a way of handling the message as it passes through individual
nodes.
- RTFM
-
Read The Fine Manual
- scalable
-
Capable of being increased in size;
More important, capable of delivering an increase in performance
proportional to an increase in size.
- scheduling
-
Deciding the order in which the calculations in
a program are to be executed and by which processes. Allocating
processes to processors is usually called mapping.
- self-scheduling
-
Automatically allocating work to processes. If
T tasks are to be done by P processors, and P < T , then they may be
self-scheduled by keeping them in a central pool from which each
processor claims a new job when it finishes executing its old one.
- semaphore
-
A data type for controlling concurrency.
A semaphore is initialized to an integer value.
Two operations may be applied to it: signal increments the
semaphore's value by one, and wait blocks its caller until the
semaphore's value is greater than zero, then decrements the semaphore.
A binary semaphore is one that can only take on the values 0 and 1.
Any other synchronization primitive can be built in terms of semaphores.
- sequential bottleneck
-
A part of a computation for which there is
little or no parallelism.
- sequential computer
-
Synonymous with a Von Neumann computer, that is,
a ``conventional'' computer in which only one processing element works
on a problem at a given time.
- shared memory
-
Real or virtual
memory that appears to users to constitute
a single address space, but which is actually physically disjoint.
Virtual shared memory is often implemented using some combination of
hashing and local caching.
Memory that appears to the user to be contained in
a single address space and that can be accessed by any process. In a
uniprocessor or multiprocessor there is typically a single memory
unit, or several memory units interleaved to give the appearance of a
single memory unit.
- shared variables
-
Variables to which two or more processes have
access, or a model of parallel computing in which interprocess
communication and synchronization are managed through such variables.
- signal
-
- SIMD
-
Single-Instruction Multiple-Data,
a category of Flynn's
taxonomy in which a single instruction stream is concurrently applied
to multiple data sets. A SIMD architecture is one in which homogeneous
processes synchronously execute the same instructions on their own
data, or one in which an operation can be executed on vectors of fixed
or varying size.
- socket
-
An endpoint for network communication.
For example, on a Unix machine, a TCP/IP connection may terminate in
a socket, which can be read or written through a file descriptor.
- space sharing
-
Dividing the resources of a parallel computer among
many programs so they can run simultaneously without affecting one
another's performance.
- spanning tree
-
A tree containing a subset of the edges in a graph
and including every node in that graph.
A spanning tree can always be
constructed so that its depth (the greatest distance between its root
and any leaf) is no greater than the diameter of the graph. Spanning
trees are frequently used to implement broadcast operations.
- spawn
-
To create a new process or PVM task, possibly different from the parent.
Compare with fork.
- speedup
-
The ratio of two program execution times, particularly
when times are from execution on 1 and P nodes of the same computer.
Speedup is usually discussed as a function of the number of
processors, but is also a function (implicitly) of the problem size.
- SPMD
-
Single-Program Multiple-Data,
a category sometimes added
to Flynn's taxonomy to describe programs made up of many instances of
a single type of process, each executing the same code independently.
SPMD can be viewed either as an extension of SIMD or as a restriction
of MIMD.
- startup cost
-
The time taken to initiate any transaction with some
entity. The startup cost of a message-passing system, for example, is
the time needed to send a message of zero length to nowhere.
- supercomputer
-
A time-dependent term that refers to the class of
most powerful computer systems worldwide at the time of reference.
- switch
-
A physical communication medium containing nodes that
perform only communications functions. Examples include crossbar
switches, in which N + M buses cross orthogonally at N M switching points
to connect
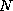 objects of one type to M objects of another, and
multistage switches in which several layers of switching nodes connect
objects of one type to objects of another type.
objects of one type to M objects of another, and
multistage switches in which several layers of switching nodes connect
objects of one type to objects of another type.
- synchronization
-
The act of bringing two or more processes to
known points in their execution at the same clock time. Explicit
synchronization is not needed in SIMD programs (in which every
processor either executes the same operation as every other or does
nothing) but is often necessary in SPMD and MIMD programs. The time
wasted by processes waiting for other processes to synchronize with
them can be a major source of inefficiency in parallel programs.
- synchronous
-
Occurring at the same clock time. For example, if a
communication event is synchronous, then there is some moment at which
both the sender and the receiver are engaged in the operation.
- task
-
The smallest component of a program addressable in PVM.
A task is generally a native ``process'' to the machine on which it
runs.
- tasker
-
A special task that manages other tasks on the same host.
It is the parent of the target tasks,
allowing it to manipulate them (e.g., for debugging or other instrumentation).
- TCP
-
Transmission Control Protocol,
a reliable host-host stream protocol for packet-switched interconnected
networks such as IP.
- thread
-
A thread of program control sharing resources (memory, I/O state)
with other threads.
A lightweight process.
- TID
-
Task Identifier,
an address used in PVM for tasks, pvmds, and multicast groups.
- time sharing
-
Sharing a processor among multiple programs.
Time sharing attempts to better utilize a CPU by overlapping I/O in
one program with computation in another.
- trace scheduling
-
A compiler optimization technique that vectorizes
the most likely path through a program as if it were a single basic
block, includes extra instructions at each branch to undo any ill
effects of having made a wrong guess, vectorizes the next most likely
branches, and so on.
- topology
-
the configuration of
the processors in a multicomputer
and the circuits in a switch.
Among the most common topologies are
the mesh, the hypercube, the butterfly,
the torus, and the shuffle exchange network.
- tuple
-
An ordered sequence of fixed length of values of arbitrary
types. Tuples are used for both data storage and interprocess
communication in the generative communication paradigm.
- tuple space
-
A repository for tuples in a generative communication
system. Tuple space is an associative memory.
- UDP
-
User Datagram Protocol,
a simple protocol allowing datagrams (blocks of data) to be sent
between hosts interconnected by networks such as IP.
UDP can duplicate or lose messages,
and imposes a length limit of 64 kbytes.
- uniprocessor
-
A computer containing a single processor. The term
is generally synonymous with scalar processor.
- virtual channel
-
A logical point-to-point connection between two
processes. Many virtual channels may time share a single link to hide
latency and to avoid deadlock.
- virtual concurrent computer
-
A computer system that is programmed
as a concurrent computer of some number of nodes P but that is
implemented either on a real concurrent computer of some number of
nodes less than P or on a uniprocessor running software to emulate the
environment of a concurrent machine. Such an emulation system is said
to provide virtual nodes to the user.
- virtual cut-through
-
A technique for routing messages in which the
head and tail of the message both proceed as rapidly as they can. If
the head is blocked because a link it wants to cross is being used by
some other message, the tail continues to advance, and the message's
contents are put into buffers on intermediate nodes.
- virtual machine
-
A multicomputer composed of separate (possibly self-complete) machines
and a software backplane to coordinate operation.
- virtual memory
-
Configuration in which
portions of the address space are kept on a secondary medium,
such as a disk or auxiliary memory.
When a reference is made to a location not resident in main memory, the
virtual memory manager
loads the location from secondary storage before the access completes.
If no space is available in main memory,
data is written to secondary storage to make some available.
Virtual memory is used by almost all uniprocessors and
multiprocessors to increase apparent memory size,
but is not available on some array processors and
multicomputers.
- virtual shared memory
-
Memory that appears to users to constitute
a single address space, but that is actually physically disjoint.
Virtual shared memory is often implemented using some combination of
hashing and local caching.
- Von Neumann architecture
-
Any computer that does
not employ concurrency or parallelism. Named after John Von Neumann
(1903-1957), who is credited with the invention of the basic
architecture of current sequential computers.
- wait context
-
A data structure used in the pvmd to hold state when a thread
of operation must be suspended,
for example, when calling a pvmd on another host.
- working set
-
Those values from shared memory that a process has
copied into its private memory, or those pages of virtual memory being
used by a process. Changes a process makes to the values in its
working set are not automatically seen by other processes.
- XDR
-
eXternal Data Representation
An Internet standard data encoding (essentially just big-endian
integers and IEEE format floating point numbers).
PVM converts data to XDR format to allow communication between hosts
with different native data formats.
Next: History of PVM
Up: Debugging the System
Previous: Sane Heap