BiCG requires computing a matrix-vector product 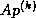 and a
transpose product
and a
transpose product 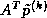 . In some applications the
latter product may be impossible to perform, for instance if the
matrix is not formed explicitly
and the regular product is only given in operation form, for instance
as a function call evaluation.
. In some applications the
latter product may be impossible to perform, for instance if the
matrix is not formed explicitly
and the regular product is only given in operation form, for instance
as a function call evaluation.
In a parallel environment , the two matrix-vector products can
theoretically be performed simultaneously; however,
in a distributed-memory environment, there will be extra communication
costs associated with one of the two matrix-vector products, depending
upon the storage scheme for 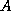 .
A duplicate copy of the
matrix will alleviate this problem, at the cost of doubling the
storage requirements for the matrix.
.
A duplicate copy of the
matrix will alleviate this problem, at the cost of doubling the
storage requirements for the matrix.
Care must also be exercised in choosing the preconditioner, since similar problems arise during the two solves involving the preconditioning matrix.
It is difficult to make a fair comparison between GMRES and BiCG. GMRES really minimizes a residual, but at the cost of increasing work for keeping all residuals orthogonal and increasing demands for memory space. BiCG does not minimize a residual, but often its accuracy is comparable to GMRES, at the cost of twice the amount of matrix vector products per iteration step. However, the generation of the basis vectors is relatively cheap and the memory requirements are modest. Several variants of BiCG have been proposed that increase the effectiveness of this class of methods in certain circumstances. These variants (CGS and Bi-CGSTAB) will be discussed in coming subsections.