Manufacturers will always feel that any benchmark not tuned specifically by themselves, is an unfair test of their hardware and software. This is inevitable and from their viewpoint it is true. NASA have overcome this problem by only specifying the problems (the NAS paper-and-pencil benchmarks [6]) and leaving the manufacturers to write the code, but in many circumstances this would require unjustifiable effort and take too long. It is also a perfectly valid question to ask how a particular parallel computer will perform on existing parallel code, and that is the viewpoint of PARKBENCH .
The benchmarking procedure is to run the distributed PARKBENCH suite on an as-is basis, making only such non-substantive changes that are required to make the code run (e.g. changing the names of header files to a local variant). The as-is run may use the highest level of automatic compiler optimisation that works, but the level used and compiler date should be noted in the appropriate subsection of the performance database entry.
After completing the as-is run, which gives a base-line result, any form of
optimisation may be applied to show the particular computer to its best
advantage, up to completely rethinking the algorithm, and rewriting
the code. The only requirement on the benchmarker is to state what has been
done. However, remember that, even if the algorithm is changed, the official
flop-count, 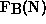 that is used in the calculation of nominal benchmark
Mflop/s,
that is used in the calculation of nominal benchmark
Mflop/s, 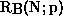 , does not. In this way a better algorithm will show up
with a higher
, does not. In this way a better algorithm will show up
with a higher 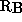 , as we would want it to, even though the hardware
Mflop/s is likely to be little changed.
, as we would want it to, even though the hardware
Mflop/s is likely to be little changed.
Typical steps in optimisation might be: