Although portable software-interfaces are available, this does not mean,
that the generated code has high efficiency on any particular machine.
Machines are too different. Some offer very fast
synchronisation-mechanisms and low latency (e.g. Cray-T3D), others have
hardware for good latency-hiding and asynchronity (e.g. intel Paragon)
and others again have only a very fast processor (e.g. IBM SP/2).
This means, that, starting with a parallelized code, there is still a
lot of effort and time to be spent, until results are satisfactory. The
following figure shows the history of LS-DYNA3D on the intel Paragon
from the parallelized version to a really usable and cost-effictive
solution. The scale on the right side shows the calculated cost relative
to one processor of a Cray C-90. This means that the initial parallel code
was neither cost-effective nor fast.
The final result however (after half a year of further optimisation)
saves about 60-70 % of the cost at about the same turnaround-time.
The testcase is a crash example from Audi.
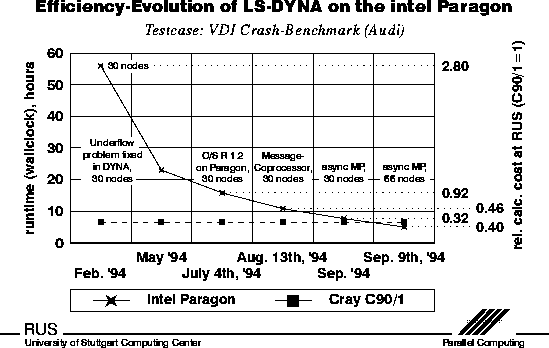
Figure 1: Are MPPs an economic solution?