Machine type: Shared-memory multi-processor.
Models: Power Challenge L, XL.
Operating system: IRIX (SGI's Unix variant).
Compilers: Fortran 77, C, C++ , Pascal.
System parameters:

Performance:

Note: The value of 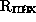 is obtained with 16 processors.
is obtained with 16 processors.
The Power Challenge systems are shared-memory multiple-instruction multiple-data parallel (MIMD) computers. So, several different instructions can be going on at the same time using different data items in these instructions. All data are stored in a single shared memory from which the multiple processors draw the data items they need and in which the results are stored again. In most high performance systems the main problem is to provide the CPUs with enough data and to transport the results back at such a rate that they can be kept busy continuously. In this, the Powerchallenge is no exception. The data is transported from the main memory to the CPUs by a central bus. The so-called POWERpath-2 bus is 256 bits wide and has a bandwidth of 1.2 GB/s. This is very fast as busses go but even then the data rates that are needed by the CPUs cannot possibly be fulfilled when no special provisions would exist. These provisions are present in the form of large data and instruction caches for each of the CPUs.
The Power Challenge series uses MIPS R8000 RISC processors(formerly called the TFP processor standing for True Floating Point) with a nominal peak speed of 300 Mflop/s. Although the clock rate of this processor is two times lower than that of its predecessor, the R4400, the performance is 4 times higher. As the need for data is even higher than that of the R4400 processors with this speed of processing, there is a special extra cache called the ``Streaming cache'' of up to 16 MB. This is very large and it should reduce the bus traffic as much as possible. All floating-point operations are done by streaming the operands from this large off-chip cache to the floating-point registers. In contrast to the R4400 processor, the R8000 is able to do a combined multiply-add operation which in many cases doubles the operation speed. In addition, the floating-point functional units are doubled with respect to the R4400 which should explain the four-fold increase in performance with respect to this predecessor.
Recently, Silicon Graphics has begun to couple a number of Power Challenge systems into a cluster of systems using PVM to communicate between them for the solution of extremely large application problems. SGI wants to extend this technique by providing faster coupling and the introduction of a ``shared-memory'' PVM which would be a message passing model that can be used homogeously (for the user) both within a Power Challenge system and between them. This trend is also to be seen with other vendors (e.g. Fujitsu and NEC).
Parallelisation is done either automatically by the (Fortran or C) compiler or explicitly by the user, mainly through the use of directives. As synchronisation, etc., has to be done via memory the parallelisation overhead is fairly large.